A notable example of a radical is the hydroxyl radical (HO•), a molecule that has one unpaired electron on the oxygen atom. Two other examples are triplet oxygen and triplet carbene (:CH2) which have two unpaired electrons.
Radicals may be generated in a number of ways, but typical methods involve redox reactions.Ionizing radiation, heat, electrical discharges, and electrolysis are known to produce radicals. Radicals are intermediates in many chemical reactions, more so than is apparent from the balanced equations.
Radicals are important in combustion,atmospheric chemistry,polymerization,plasma chemistry, biochemistry, and many other chemical processes. A majority of natural products are generated by radical-generating enzymes. In living organisms, the radicals superoxide and nitric oxide and their reaction products regulate many processes, such as control of vascular tone and thus blood pressure. They also play a key role in the intermediary metabolism of various biological compounds. Such radicals can even be messengers in a process dubbed redox signaling. A radical may be trapped within a solvent cage or be otherwise bound. (W)
A single strand of a nucleic acid molecule has a phosphoryl end, called the 5′-end, and a hydroxyl or 3′-end. These define the 5′→3′ direction. There are three reading frames that can be read in this 5′→3′ direction, each beginning from a different nucleotide in a triplet. In a double stranded nucleic acid, an additional three reading frames may be read from the other, complementary strand in the 5′→3′ direction along this strand. As the two strands of a double-stranded nucleic acid molecule are antiparallel, the 5′→3′ direction on the second strand corresponds to the 3′→5′ direction along the first strand.
In general, at the most, one reading frame in a given section of a nucleic acid, is biologically relevant (open reading frame). Some viral transcripts can be translated using multiple, overlapping reading frames. There is one known example of overlapping reading frames in mammalian mitochondrial DNA: coding portions of genes for 2 subunits of ATPase overlap. (W)
Illustration of possible reading frames: AGG·TGA·CAC·CGC·AAG·CCT·TAT·ATT·AGC A·GGT·GAC·ACC·GCA·AGC·CTT·ATA·TTA·GC AG·GTG·ACA·CCG·CAA·GCC·TTA·TAT·TAG·C.
An example of a six-frame translation.
The two reading frames used by the human mitochondrial genes MT-ATP8 and MT-ATP6.
The human genes MT-ATP8 and MT-ATP6 located in the mitochondrial DNA and coding for the ATP synthase F0 subunits 8 and 6 overlap on 46 nucleotides. The DNA sequence of this region of the human mitochondrial genome is given in black (positions 8,525 to 8,580 in the sequence accession NC_012920). There are three possible reading frames in the 5' -> 3' forward direction, starting on the first (+1), second (+2) and third position (+3). For each nucleotide triplet (square brackets), the corresponding amino acid is given (one-letter code), either in the +1 frame for MT-ATP8 (in red) or in the +3 frame for MT-ATP6 (in blue). The MT-ATP8 genes terminates with the TAG stop codon (red dot) in the +1 frame. The MT-ATP6 gene starts with the ATG codon (blue circle for the M amino acid) in the +3 frame. Forteen sense codons do overlap for the two genes. As both genes use different ORF, the two protein sequences are different in the overlap region.
real-time polymerase chain reaction
A real-time polymerase chain reaction (real-time PCR), also known as quantitative Polymerase Chain Reaction (qPCR), is a laboratory technique of molecular biology based on the polymerase chain reaction (PCR). It monitors the amplification of a targeted DNA molecule during the PCR (i.e., in real time), not at its end, as in conventional PCR. Real-time PCR can be used quantitatively (quantitative real-time PCR) and semi-quantitatively (i.e., above/below a certain amount of DNA molecules) (semi-quantitative real-time PCR).
Two common methods for the detection of PCR products in real-time PCR are (1) non-specific fluorescent dyes that intercalate with any double-stranded DNA and (2) sequence-specific DNA probes consisting of oligonucleotides that are labelled with a fluorescent reporter, which permits detection only after hybridization of the probe with its complementary sequence.
(1) In intact probes, reporter fluorescence is quenched. (2) Probes and the complementary DNA strand are hybridized and reporter fluorescence is still quenched. (3) During PCR, the probe is degraded by the Taq polymerase and the fluorescent reporter released.
reassortmentReassortment is the mixing of the genetic material of a species into new combinations in different individuals. Several different processes contribute to reassortment, including assortment of chromosomes, and chromosomal crossover. It is particularly used when two similar viruses that are infecting the same cell exchange genetic material. In particular, reassortment occurs among influenza viruses, whose genomes consist of eight distinct segments of RNA. These segments act like mini-chromosomes, and each time a flu virus is assembled, it requires one copy of each segment.(W)
The process of reassortment in biotechnology.
receptor (biochemistry)
In biochemistry and pharmacology,receptors are chemical structures, composed of protein, that receive and transduce signals that may be integrated into biological systems. These signals are typically chemical messengers which bind to a receptor and cause some form of cellular/tissue response, e.g. a change in the electrical activity of a cell. There are three main ways the action of the receptor can be classified: relay of signal, amplification, or integration Relaying sends the signal onward, amplification increases the effect of a single ligand, and integration allows the signal to be incorporated into another biochemical pathway. (W)
An example of membrane receptors. Ligands, located outside the cell Ligands connect to specific receptor proteins based on the shape of the active site of the protein. The receptor releases a messenger once the ligand has connected to the receptor.
An example of membrane receptors.
Ligands, located outside the cell
Ligands connect to specific receptor proteins based on the shape of the active site of the protein.
The receptor releases a messenger once the ligand has connected to the receptor.
Recombinant DNA (rDNA) molecules are DNA molecules formed by laboratory methods of genetic recombination (such as molecular cloning) to bring together genetic material from multiple sources, creating sequences that would not otherwise be found in the genome.
Recombinant DNA is the general name for a piece of DNA that has been created by combining at least two fragments from two different sources. Recombinant DNA is possible because DNA molecules from all organisms share the same chemical structure, and differ only in the nucleotide sequence within that identical overall structure. Recombinant DNA molecules are sometimes called chimeric DNA, because they can be made of material from two different species, like the mythical chimera. R-DNA technology uses palindromic sequences and leads to the production of sticky and blunt ends.(W)
Construction of recombinant DNA, in which a foreign DNA fragment is inserted into a plasmid vector. In this example, the gene indicated by the white color is inactivated upon insertion of the foreign DNA fragment.
redox (reduction-oxidation)
Redox (reduction–oxidation) is a type of chemical reaction in which the oxidation states of atoms are changed. Redox reactions are characterized by the actual or formal transfer of electrons between chemical species, most often with one species (the reducing agent) undergoing oxidation (losing electrons) while another species (the oxidizing agent) undergoes reduction (gains electrons). The chemical species from which the electron is removed is said to have been oxidized, while the chemical species to which the electron is added is said to have been reduced. In other words:
Oxidation is the loss of electrons or an increase in the oxidation state of an atom, an ion, or of certain atoms in a molecule.
Reduction is the gain of electrons or a decrease in the oxidation state of an atom, an ion, or of certain atoms in a molecule. (W)
Sodium and fluorine atoms undergoing a redox reaction to form sodium fluoride. Sodium loses its outer electron to give it a stable electron configuration, and this electron enters the fluorine atom exothermically. The oppositely charged ions – typically a great many of them – are then attracted to each other to form a solid.
Regulation of gene expression, or gene regulation, includes a wide range of mechanisms that are used by cells to increase or decrease the production of specific gene products (protein or RNA). Sophisticated programs of gene expression are widely observed in biology, for example to trigger developmental pathways, respond to environmental stimuli, or adapt to new food sources. Virtually any step of gene expression can be modulated, from transcriptional initiation, to RNA processing, and to the post-translational modification of a protein. Often, one gene regulator controls another, and so on, in a gene regulatory network.
Gene regulation is essential for viruses,prokaryotes and eukaryotes as it increases the versatility and adaptability of an organism by allowing the cell to express protein when needed. Although as early as 1951, Barbara McClintock showed interaction between two genetic loci, Activator (Ac) and Dissociator (Ds), in the color formation of maize seeds, the first discovery of a gene regulation system is widely considered to be the identification in 1961 of the lac operon, discovered by François Jacob and Jacques Monod, in which some enzymes involved in lactose metabolism are expressed by E. coli only in the presence of lactose and absence of glucose.
In multicellular organisms, gene regulation drives cellular differentiation and morphogenesis in the embryo, leading to the creation of different cell types that possess different gene expression profiles from the same genome sequence. Although this does not explain how gene regulation originated, evolutionary biologists include it as a partial explanation of how evolution works at a molecular level, and it is central to the science of evolutionary developmental biology ("evo-devo"). (W)
Regulation of gene expression by a hormone receptor. (Regulation of gene expression by steroid hormone receptor.) (W)
Diagram showing at which stages in the DNA-mRNA-protein pathway expression can be controlled.
Histone tails and their function in chromatin formation.
(a) The flexible amino- terminal tail of each histone extends from the surface of the histone octamer. (b) In 30-nm fibers, the histone tails of one nucleosome interact with the histones and DNA of adjacent nucleosomes. In some chromatin, histone tails also interact with non-histone proteins (green) that help package the DNA. Linker histones (histone H1, red) also contribute to chromatin formation. Acetylation of histone tails alters their interaction with other nucleosomes and non-histone proteins, generally resulting in a more open chromatin structure.
1: RNA Polymerase, 2: Repressor, 3: Promoter, 4: Operator, 5: Lactose, 6: lacZ, 7: lacY, 8: lacA. Top: The gene is essentially turned off. There is no lactose to inhibit the repressor, so the repressor binds to the operator, which obstructs the RNA polymerase from binding to the promoter and making lactase. Bottom: The gene is turned on. Lactose is inhibiting the repressor, allowing the RNA polymerase to bind with the promoter, and express the genes, which synthesize lactase. Eventually, the lactase will digest all of the lactose, until there is none to bind to the repressor. The repressor will then bind to the operator, stopping the manufacture of lactase.
1: RNA Polymerase, 2: Repressor, 3: Promoter, 4: Operator, 5: Lactose, 6: lacZ, 7: lacY, 8: lacA. Top: The gene is essentially turned off. There is no lactose to inhibit the repressor, so the repressor binds to the operator, which obstructs the RNA polymerase from binding to the promoter and making lactase. Bottom: The gene is turned on. Lactose is inhibiting the repressor, allowing the RNA polymerase to bind with the promoter, and express the genes, which synthesize lactase. Eventually, the lactase will digest all of the lactose, until there is none to bind to the repressor. The repressor will then bind to the operator, stopping the manufacture of lactase.
regulation of transcription in cancer
Generally, in progression to cancer, hundreds of genes are silenced or activated. Although silencing of some genes in cancers occurs by mutation, a large proportion of carcinogenic gene silencing is a result of altered DNA methylation (see DNA methylation in cancer). DNA methylation causing silencing in cancer typically occurs at multiple CpG sites in the CpG islands that are present in the promoters of protein coding genes.
Altered expressions of microRNAs also silence or activate many genes in progression to cancer (see microRNAs in cancer). Altered microRNA expression occurs through hyper/hypo-methylation of CpG sites in CpG islands in promoters controlling transcription of the microRNAs.
Silencing of DNA repair genes through methylation of CpG islands in their promoters appears to be especially important in progression to cancer (see methylation of DNA repair genes in cancer).(W)
For most prokaryoticchromosomes, the replicon is the entire chromosome. One notable exception found comes from archaea, where two Sulfolobus species have been shown to contain three replicons. Examples of bacterial species that have been found to possess multiple replicons include: Rhodobacter sphaeroides (2), Vibrio cholerae, and Burkholderia multivorans (3). These "secondary" (or tertiary) chromosomes are often described as a molecule that is a mixture between a true chromosome and a plasmid and are sometimes called "chromids". Various Azospirillum species possess 7 replicons, Azospirillum lipoferum, for instance, has 1 bacterial chromosome, 5 chromids, and 1 plasmid. Plasmids and bacteriophages are usually replicated as single replicons, but large plasmids in Gram-negative bacteria have been shown to carry several replicons.
Eukaryotes
For eukaryotic chromosomes, there are multiple replicons per chromosome. In the case of mitochondria the definition of replicons is somewhat confused, as they use unidirectional replication with two separate origins. (W)
DNA replication (comparing Prokaryotic to Eukaryotic
The replisome is a complex molecular machine that carries out replication of DNA. The replisome first unwinds double stranded DNA into two single strands. For each of the resulting single strands, a new complementary sequence of DNA is synthesized. The net result is formation of two new double stranded DNA sequences that are exact copies of the original double stranded DNA sequence.
A representation of the structures of the replisome during DNA replication.
DNA replication or DNA synthesis is the process of copying a double-stranded DNA molecule. This process is paramount to all life as we know it.
Eukaryotic replisome complex and associated proteins. A loop occurs in the lagging strand. (W)
repressor
In molecular genetics, a repressor is a DNA- or RNA-binding protein that inhibits the expression of one or more genes by binding to the operator or associated silencers. A DNA-binding repressor blocks the attachment of RNA polymerase to the promoter, thus preventing transcription of the genes into messenger RNA. An RNA-binding repressor binds to the mRNA and prevents translation of the mRNA into protein. This blocking of expression is called repression.(W)
The lac operon:1: RNA Polymerase, 2: lac repressor,3: Promoter, 4: Operator, 5: Lactose, 6: lacZ, 7: lacY, 8: lacA.Top: The gene is essentially turned off. There is no lactose to inhibit the repressor, so the repressor binds to the operator, which obstructs the RNA polymerase from binding to the promoter and making lactase. Bottom: The gene is turned on. Lactose is inhibiting the repressor, allowing the RNA polymerase to bind with the promoter, and express the genes, which synthesize lactase. Eventually, the lactase will digest all of the lactose, until there is none to bind to the repressor. The repressor will then bind to the operator, stopping the manufacture of lactase.
The concept that suggested this term is presumably the nature of the condensation reaction by which such classes of monomeric building blocks, such as amino acids or monosaccharides, are strung together to form a polymeric chain, such as a polysaccharide or a peptide; some atoms, typically in the form of a water molecule, are discarded from each building block, leaving only a "residue" of the building block, that ends up in the finished product. A residue might be one amino acid in a polypeptide or one monosaccharide in a starch molecule. (W)
A restriction enzyme, restriction endonuclease, or restrictaseis an enzyme that cleaves DNA into fragments at or near specific recognition sites within molecules known as restriction sites. Restriction enzymes are one class of the broader endonuclease group of enzymes. Restriction enzymes are commonly classified into five types, which differ in their structure and whether they cut their DNA substrate at their recognition site, or if the recognition and cleavage sites are separate from one another. To cut DNA, all restriction enzymes make two incisions, once through each sugar-phosphate backbone (i.e. each strand) of the DNA double helix..
These enzymes are found in bacteria and archaea and provide a defense mechanism against invading viruses. Inside a prokaryote, the restriction enzymes selectively cut up foreign DNA in a process called restriction digestion; meanwhile, host DNA is protected by a modification enzyme (a methyltransferase) that modifies the prokaryotic DNA and blocks cleavage. Together, these two processes form the restriction modification system.
Over 3,000 restriction enzymes have been studied in detail, and more than 600 of these are available commercially. These enzymes are routinely used for DNA modification in laboratories, and they are a vital tool in molecular cloning. (W)
A palindromic recognition site reads the same on the reverse strand as it does on the forward strand when both are read in the same orientation.
restriction fragment length polymorphism
In molecular biology,restriction fragment length polymorphism (RFLP) is a technique that exploits variations in homologousDNA sequences, known as polymorphisms, in order to distinguish individuals, populations, or species or to pinpoint the locations of genes within a sequence.The term may refer to a polymorphism itself, as detected through the differing locations of restriction enzyme sites, or to a related laboratory technique by which such differences can be illustrated. In RFLP analysis, a DNA sample is digested into fragments by one or more restriction enzymes, and the resulting restriction fragments are then separated by gel electrophoresis according to their size.
Although now largely obsolete due to the emergence of inexpensive DNA sequencing technologies, RFLP analysis was the first DNA profiling technique inexpensive enough to see widespread application. RFLP analysis was an important early tool in genome mapping, localization of genes for genetic disorders, determination of risk for disease, and paternity testing.(W)
restriction modification system
The restriction modification system (RM system) is found in bacteria and other prokaryotic organisms, and provides a defense against foreign DNA, such as that borne by bacteriophages.
Bacteria have restriction enzymes, also called restriction endonucleases, which cleave double stranded DNA at specific points into fragments, which are then degraded further by other endonucleases. This prevents infection by effectively destroying the foreign DNA introduced by an infectious agent (such as a bacteriophage). Approximately one-quarter of known bacteria possess RM systems and of those about one-half have more than one type of system.
As the sequences recognized by the restriction enzymes are very short, the bacterium itself will almost certainly contain some within its genome. In order to prevent destruction of its own DNA by the restriction enzymes, methyl groups are added. These modifications must not interfere with the DNA base-pairing, and therefore, usually only a few specific bases are modified on each strand.
Endonucleases cleave internal/non-terminal phosphodiester bonds. They do so only after recognising specific sequences in DNA which are usually 4-6 base pairs long, and often palindromic.(W)
restriction siteRestriction sites, or restriction recognition sites, are located on a DNA molecule containing specific (4-8 base pairs in length) sequences of nucleotides, which are recognized by restriction enzymes. These are generally palindromic sequences (because restriction enzymes usually bind as homodimers), and a particular restriction enzyme may cut the sequence between two nucleotides within its recognition site, or somewhere nearby. (W)
retrotransposonRetrotransposons (also called Class I transposable elements or transposons via RNA intermediates) are a type of genetic component that copy and paste themselves into different genomic locations (transposon) by converting RNA back into DNA through the process reverse transcription using an RNA transposition intermediate.
Through reverse transcription, retrotransposons amplify themselves quickly to become abundant in eukaryotic genomes such as maize (49–78%) and humans (42%). They are only present in eukaryotes but share features with retroviruses such as HIV, for example, discontinuous reverse transcriptase-mediated extrachromosomal recombination
There are two main types of retrotransposon, long terminal repeats (LTRs) and non-long terminal repeats (non-LTRs). Retrotransposons are classified based on sequence and method of transposition. Most retrotransposons in the maize genome are LTR, whereas in humans they are mostly non-LTR. Retrotransposons (mostly of the LTR type) can be passed onto the next generation of a host species through the germline.
The other type of transposon is the DNA transposon. DNA transposons insert themselves into different genomic locations without copying themselves that can cause harmful mutations (see horizontal gene transfer). Hence retrotransposons can be thought of as replicative, whereas DNA transposons are non-replicative. Due to their replicative nature, retrotransposons can increase eukaryotic genome size quickly and survive in eukaryotic genomes permanently. It is thought that staying in eukaryotic genomes for such long periods gave rise to special insertion methods that do not affect eukaryotic gene function drastically. (W)
Simplified representation of the life cycle of a retrotransposon.
retrovirus
A retrovirus is a type of virus that inserts a copy of its RNA genome[a] into the DNA of a host cell that it invades, thus changing the genome of that cell. Once inside the host cell's cytoplasm, the virus uses its own reverse transcriptase enzyme to produce DNA from its RNA genome, the reverse of the usual pattern, thus retro (backwards). The new DNA is then incorporated into the host cell genome by an integrase enzyme, at which point the retroviral DNA is referred to as a provirus. The host cell then treats the viral DNA as part of its own genome, transcribing and translating the viral genes along with the cell's own genes, producing the proteins required to assemble new copies of the virus.
Although retroviruses have different subfamilies, they have three basic groups. The oncoretroviruses (oncogenic retroviruses), the lentiviruses (slow retroviruses) and the spumaviruses (foamy viruses). The oncoretroviruses are able to cause cancer in some species, the lentiviruses able to cause severe immunodeficiency and death in humans and other animals, and the spumaviruses are benign and not linked to any disease in humans or animals.
Many retroviruses cause serious diseases in humans, other mammals, and birds. Human retroviruses include HIV-1 and HIV-2, the cause of the disease AIDS. Also, human T-lymphotropic virus (HTLV) causes disease in humans. The murine leukemia viruses (MLVs) cause cancer in mouse hosts. Retroviruses are valuable research tools in molecular biology, and they have been used successfully in gene delivery systems. (W)
Hiv gross.
The genomic and subgenomic organization of a prototypical retrovirus. Abbreviations are explained in the file description.
A retrovirus has a membrane containing glycoproteins, which are able to bind to a receptor protein on a host cell. There are two strands of RNA within the cell that have three enzymes: protease, reverse transcriptase, and integrase (1). The first step of replication is the binding of the glycoprotein to the receptor protein (2). Once these have been bound, the cell membrane degrades, becoming part of the host cell, and the RNA strands and enzymes enter the cell (3). Within the cell, reverse transcriptase creates a complementary strand of DNA from the retrovirus RNA and the RNA is degraded; this strand of DNA is known as cDNA (4). The cDNA is then replicated, and the two strands form a weak bond and enter the nucleus (5). Once in the nucleus, the DNA is integrated into the host cell's DNA with the help of integrase (6). This cell can either stay dormant, or RNA may be synthesized from the DNA and used to create the proteins for a new retrovirus (7). Ribosome units are used to translate the mRNA of the virus into the amino acid sequences which can be made into proteins in the rough endoplasmic reticulum. This step will also make viral enzymes and capsid proteins (8). Viral RNA will be made in the nucleus. These pieces are then gathered together and are pinched off of the cell membrane as a new retrovirus (9).
Phylogeny of Retroviruses.
reverse transcriptase
A reverse transcriptase (RT) is an enzyme used to generate complementary DNA (cDNA) from an RNA template, a process termed reverse transcription. Reverse transcriptases are used by certain viruses such as HIV and the hepatitis B virus to replicate their genomes, by retrotransposon mobile genetic elements to proliferate within the host genome, and by eukaryotic cells to extend the telomeres at the ends of their linear chromosomes. The process is notable for violating the linear flow of genetic information as described by the classical central dogma.
Retroviral RT has three sequential biochemical activities: RNA-dependent DNA polymerase activity, ribonuclease H (RNase H), and DNA-dependent DNA polymerase activity. Collectively, these activities enable the enzyme to convert single-stranded RNA into double-stranded cDNA. In retroviruses and retrotransposons, this cDNA can then integrate into the host genome, from which new RNA copies can be made via host-cell transcription. The same sequence of reactions is widely used in the laboratory to convert RNA to DNA for use in molecular cloning,RNA sequencing,polymerase chain reaction (PCR), or genome analysis. (W)
Surface representation of the crystal structure of wild-type HIV-1 Reverse Transcriptase, based on PDB 3KLF. The active sites of polymerase and RNase are highlighted.
Mechanism of reverse transcription in HIV. Step numbers will not match up..
Mechanism of reverse transcription in class VI virus ssRNA-RT,human immunodeficiency virus (HIV). Key: U3 - promoter region, U5 - recognition site for viral integrase; PBS - primer binding site; PP - polypurine section (polypurine tract); gag, pol, env - see HIV genome organisation). Colors mark complementary sequences. This diagram isn't drawn to scale. Reverse transcription occurs in the cytoplasm of host cell. In this process, viral ssRNA is transcribed by the viral reverse transcriptase (RT) into double stranded DNA. Reverse transcription takes place in 5'→3' direction. tRNA ("cloverleaf") hybridizes to PBS and provides -OH group for initiation of reverse transcription. 1) Strong stop complementary DNA (cDNA) is formed. 2) Template in RNA:DNA hybrid is degraded by RNase H domain of reverse transcriptase 3) DNA:tRNA is transferred to the 3'-end of the template (synthesis "jumps"). 4) First strand synthesis takes place. 5) The rest of viral ssRNA is degraded by RNase H, except for PP site. 6) Synthesis of second strand of ssDNA is initiated from the 3'-end of the template. tRNA is necessary to synthesis of complementary PBS 7) tRNA is degraded 8) After another "jump", PBS from the second strand hybridizes with the complementary PBS on the first strand. 9) Synthesis of both strands is completed by the DNAP function of reverse transcriptase. Both dsDNA ends have U3-R-U5 sequences, so called long terminal repeat sequences (3'LTR and 5'LTR, respectively). LTRs mediate integration of the retroviral DNA into another region of the host genome. Sources: Alan Cann: Principles of molecular virology. Amsterdam: Elsevier Academic Press, 2005, p. 93 ISBN 0-12-088787-8.; en:Reverse transcription entry in Wikipedia.
Some viruses (such as HIV, the cause of AIDS), have the ability to transcribe RNA into DNA. HIV has an RNA genome that is reverse transcribed into DNA. The resulting DNA can be merged with the DNA genome of the host cell. The main enzyme responsible for synthesis of DNA from an RNA template is called reverse transcriptase.
In the case of HIV, reverse transcriptase is responsible for synthesizing a complementary DNA strand (cDNA) to the viral RNA genome. The enzyme ribonuclease H then digests the RNA strand, and reverse transcriptase synthesises a complementary strand of DNA to form a double helix DNA structure ("cDNA"). The cDNA is integrated into the host cell's genome by the enzyme integrase, which causes the host cell to generate viral proteins that reassemble into new viral particles. In HIV, subsequent to this, the host cell undergoes programmed cell death, or apoptosis of T cells. However, in other retroviruses, the host cell remains intact as the virus buds out of the cell.
Some eukaryotic cells contain an enzyme with reverse transcription activity called telomerase. Telomerase is a reverse transcriptase that lengthens the ends of linear chromosomes. Telomerase carries an RNA template from which it synthesizes a repeating sequence of DNA, or "junk" DNA. This repeated sequence of DNA is called a telomere and can be thought of as a "cap" for a chromosome. It is important because every time a linear chromosome is duplicated, it is shortened. With this "junk" DNA or "cap" at the ends of chromosomes, the shortening eliminates some of the non-essential, repeated sequence rather than the protein-encoding DNA sequence, that is farther away from the chromosome end.
Telomerase is often activated in cancer cells to enable cancer cells to duplicate their genomes indefinitely without losing important protein-coding DNA sequence. Activation of telomerase could be part of the process that allows cancer cells to become immortal. The immortalizing factor of cancer via telomere lengthening due to telomerase has been proven to occur in 90% of all carcinogenic tumors in vivo with the remaining 10% using an alternative telomere maintenance route called ALT or Alternative Lengthening of Telomeres. (W)
Reverse transcription polymerase chain reaction (RT-PCR) is a laboratory technique combining reverse transcription of RNA into DNA (in this context called complementary DNA or cDNA) and amplification of specific DNA targets using polymerase chain reaction (PCR). It is primarily used to measure the amount of a specific RNA. This is achieved by monitoring the amplification reaction using fluorescence, a technique called real-time PCR or quantitative PCR (qPCR). Combined RT-PCR and qPCR are routinely used for analysis of gene expression and quantification of viral RNA in research and clinical settings. (W)
Reverse Transcription - PCR cDNA Synthesis from mRNA by using M-MuLV reverse transcriptase and cDNA Amplification with specific primers by using Taq Polymerase.
ribonucleaseRibonuclease (commonly abbreviated RNase) is a type of nuclease that catalyzes the degradation of RNA into smaller components. Ribonucleases can be divided into endoribonucleases and exoribonucleases, and comprise several sub-classes within the EC 2.7 (for the phosphorolytic enzymes) and 3.1 (for the hydrolytic enzymes) classes of enzymes.(W)
Ribonuclease.
Crystal structure of Ustilago sphaerogena Ribonuclease U2 Complexed with AMP.
ribonuclease PRibonuclease P (EC3.1.26.5,RNase P) is a type of ribonuclease which cleaves RNA. RNase P is unique from other RNases in that it is a ribozyme – a ribonucleic acid that acts as a catalyst in the same way that a protein-based enzyme would. Its function is to cleave off an extra, or precursor, sequence of RNA on tRNA molecules. Further, RNase P is one of two known multiple turnover ribozymes in nature (the other being the ribosome), the discovery of which earned Sidney Altman and Thomas Cech the Nobel Prize in Chemistry in 1989: in the 1970s, Altman discovered the existence of precursor tRNA with flanking sequences and was the first to characterize RNase P and its activity in processing of the 5' leader sequence of precursor tRNA. Recent findings also reveal that RNase P has a new function. It has been shown that human nuclear RNase P is required for the normal and efficient transcription of various small noncoding RNAs, such as tRNA, 5S rRNA,SRP RNA and U6 snRNA genes, which are transcribed by RNA polymerase III, one of three major nuclear RNA polymerases in human cells. (W)
Structure of a bacterial ribonuclease P holoenzyme in complex with tRNA.
Crystal structure of a bacterial ribonuclease P holoenzyme in complex with tRNA (yellow), showing metal ions involved in catalysis (pink spheres), PDB:3Q1R.
In biochemistry, a ribonucleotide is a nucleotide containing ribose as its pentose component. It is considered a molecular precursor of nucleic acids. Nucleotides are the basic building blocks of DNA and RNA. The monomer itself from ribonucleotides forms the basic building blocks for RNA. However, the reduction of ribonucleotide, by enzyme ribonucleotide reductase (RNR), forms deoxyribonucleotide, which is the essential building block for DNA. There are several differences between DNA deoxyribonucleotides and RNA ribonucleotides. Successive nucleotides are linked together via phosphodiester bonds by 3'-5'.
Ribonucleotides are also utilized in other cellular functions. These special monomers are utilized in both cell regulation and cell signaling as seen in adenosine-monophosphate (AMP). Furthermore, ribonucleotides can be converted to adenosine triphosphate (ATP), the energy currency in organisms. Ribonucleotides can be converted to cyclic adenosine monophosphate (cyclic AMP) to regulate hormones in organisms as well. In living organisms, the most common bases for ribonucleotides are adenine (A), guanine (G), cytosine (C), or uracil (U). The nitrogenous bases are classified into two parent compounds, purine and pyrimidine.(W)
General Ribonucleotide Structure: phosphate group, Ribose, Nucleobase.
ribophorinRibophorins are dome shaped transmembrane glycoproteins which are located in the membrane of the rough endoplasmic reticulum, but are absent in the membrane of the smooth endoplasmic reticulum. There are two types of ribophorines: ribophorin I and II. These act in the proteic complex oligosaccharyltransferase (OST) as two different subunits of the named complex. Ribophorin I and II are only present in eukaryote cells.(W)
Ribophorin is a subunit of oligosaccharide transferase in the RER.
Fischer projection of the aldopentose monosaccharide, D-ribose..
l-ribose.
ribosomal DNA
Ribosomal DNA (rDNA) is a DNA sequence that codes for ribosomal RNA.Ribosomes are assemblies of proteins and rRNA molecules that translatemRNA molecules to produce proteins. As shown in the figure, rDNA of eukaryotes consists of a tandem repeat of a unit segment, composed of NTS, ETS, 18S,ITS1,5.8S,ITS2, and 28S tracts. rDNA has another gene, coding for 5S rRNA, located in the genome in most eukaryotes. 5S rDNA is also present in tandem repeats as in Drosophila. DNA regions that are repetitive often undergo recombination events. The rDNA repeats have many regulatory mechanisms that keep the DNA from undergoing mutations, thus keeping the rDNA conserved. (W)
The gene segment of eukaryotic rDNA contains 18S, 5.8S, and 28S tracts and forms a tandem repetitive cluster; the 5S rDNA is coded separately. NTS, nontranscribed spacer, ETS, external transcribed spacer, ITS, internal transcribed spacers 1 and 2, numbered from 5' end.
Nucleolus with pre-rRNA components.
ribosomal RNA
Ribosomal ribonucleic acid (rRNA) is a type of non-coding RNA which is the primary component of ribosomes, essential to all cells. rRNA is a ribozyme which carries out protein synthesis in ribosomes. Ribosomal RNA is transcribed from ribosomal DNA (rDNA) and then bound to ribosomal proteins to form small and large ribosome subunits. rRNA is the physical and mechanical actor of the ribosome that forces transfer RNA (tRNA) and messenger RNA (mRNA) to process and translate the latter into proteins. Ribosomal RNA is the predominant form of RNA found in most cells; it makes up about 80% of cellular RNA despite never being translated into proteins itself. Ribosomes are composed of approximately 60% rRNA and 40% ribosomal proteins by mass. (W)
Three-dimensional views of the ribosome, showing rRNA in dark blue (small subunit) and dark red (large subunit). Lighter colors represent ribosomal proteins..
ribozyme
Ribozymes (ribonucleic acid enzymes) are RNA molecules that have the ability to catalyze specific biochemical reactions, including RNA splicing in gene expression, similar to the action of protein enzymes. The 1982 discovery of ribozymes demonstrated that RNA can be both genetic material (like DNA) and a biological catalyst (like protein enzymes), and contributed to the RNA world hypothesis, which suggests that RNA may have been important in the evolution of prebiotic self-replicating systems. The most common activities of natural or in vitro-evolved ribozymes are the cleavage or ligation of RNA and DNA and peptide bond formation. Within the ribosome, ribozymes function as part of the large subunit ribosomal RNA to link amino acids during protein synthesis. They also participate in a variety of RNA processing reactions, including RNA splicing,viral replication, and transfer RNA biosynthesis. Examples of ribozymes include the hammerhead ribozyme, the VS ribozyme,Leadzyme and the hairpin ribozyme.(W)
Some RNA molecules play an active role within cells by catalyzing biological reactions, controlling gene expression, or sensing and communicating responses to cellular signals. One of these active processes is protein synthesis, a universal function in which RNA molecules direct the synthesis of proteins on ribosomes. This process uses transfer RNA (tRNA) molecules to deliver amino acids to the ribosome, where ribosomal RNA(rRNA) then links amino acids together to form coded proteins. (W)
A hairpin loop from a pre-mRNA. Highlighted are the nucleobases (green) and the ribose-phosphate backbone (blue). This is a single strand of RNA that folds back upon itself.
There are three different types of RNA that perform separate jobs in order to make proteins. Ribosomes are made of one light subunit and one heavy subunit. Each subunit is made of proteins and ribosomal RNA or rRNA. Messenger RNA, or mRNA, binds to the ribosome to initiate protein synthesis. Transfer RNA, or tRNA, binds to specific amino acids in the cytoplasm and carries them to the ribosome for the assembly of amino acids into a protein. Along the mRNA strand, each group of three consecutive nucleotides, called a codon, specifies a single amino acid. The sequence of codons along the length of the mRNA strand determines the order of amino acids in the new protein.
RNA-binding proteinRNA-binding proteins (often abbreviated as RBPs) are proteins that bind to the double or single stranded RNA in cells and participate in forming ribonucleoprotein complexes. RBPs contain various structural motifs, such as RNA recognition motif (RRM), dsRNA binding domain,zinc finger and others. They are cytoplasmic and nuclear proteins. However, since most mature RNA is exported from the nucleus relatively quickly, most RBPs in the nucleus exist as complexes of protein and pre-mRNA called heterogeneous ribonucleoprotein particles (hnRNPs). RBPs have crucial roles in various cellular processes such as: cellular function, transport and localization. They especially play a major role in post-transcriptional control of RNAs, such as: splicing,polyadenylation,mRNA stabilization, mRNA localization and translation.Eukaryotic cells encode diverse RBPs, approximately 500 genes, with unique RNA-binding activity and protein–protein interaction. During evolution, the diversity of RBPs greatly increased with the increase in the number of introns. Diversity enabled eukaryotic cells to utilize RNA exons in various arrangements, giving rise to a unique RNP (ribonucleoprotein) for each RNA. Although RBPs have a crucial role in post-transcriptional regulation in gene expression, relatively few RBPs have been studied systematically. (W)
ADAR : an RNA binding protein involved in RNA editing events.
RNA editing
RNA editing (also RNA modification) is a molecular process through which some cells can make discrete changes to specific nucleotide sequences within an RNA molecule after it has been generated by RNA polymerase. It occurs in all living organisms, and is one of the most evolutionarily conserved properties of RNAs. RNA editing may include the insertion, deletion, and base substitution of nucleotides within the RNA molecule. RNA editing is relatively rare, with common forms of RNA processing (e.g. splicing, 5'-capping, and 3'-polyadenylation) not usually considered as editing. It can affect the activity, localization as well as stability of RNAs, and has been linked with human diseases.
RNA editing has been observed in some tRNA,rRNA,mRNA, or miRNA molecules of eukaryotes and their viruses,archaea, and prokaryotes. RNA editing occurs in the cell nucleus and cytosol, as well as within mitochondria and plastids. In vertebrates, editing is rare and usually consists of a small number of changes to the sequence of the affected molecules. In other organisms, such as squids, extensive editing (pan-editing) can occur; in some cases the majority of nucleotides in an mRNA sequence may result from editing. More than 160 types of RNA modifications have been described so far.
RNA-editing processes show great molecular diversity, and some appear to be evolutionarily recent acquisitions that arose independently. The diversity of RNA editing phenomena includes nucleobase modifications such as cytidine (C) to uridine (U) and adenosine (A) to inosine (I) deaminations, as well as non-template nucleotide additions and insertions. RNA editing in mRNAs effectively alters the amino acid sequence of the encoded protein so that it differs from that predicted by the genomic DNA sequence. (W)
The Editosome Complex (Personal Rendition of how the Editosome Complex should look like, as described in other studies by researchers) (W)
The PIWI domain of an Argonaute protein in complex with double-stranded RNA.
The PIWI domain of an argonaute protein from A. fulgidus, bound to a short double-stranded RNA fragment and illustrating the base-pairing and aromatic stacking stabilization of the bound conformation. The binding of the argonaute-containing RISC complex to the 5' end of the guide strand is critical in the process of RNA interference. The protein is shown colored by secondary structure and the dsRNA colored by element; a conserved tyrosine residue involved in aromatic stacking is shown in light blue, and the divalent cation (magnesium) is the gray sphere.
Part of the RNA interference pathway with the different ways RISC can silence genes via their messenger RNA.
Part of the RNA interference pathway focusing on the involvement of the RNA-induced silencing complex (RISC). This includes RISC binding double-stranded RNA, cleaving one of the strands and using the other to target complementary messenger RNA to silence certain genes.
A full-length argonaute protein from the archaea species Pyrococcus furiosus.
An argonaute protein from Pyrococcus furiosus; these proteins are the catalytic endonucleases in the RNA-induced silencing complex, the protein complex that mediates the RNA interference phenomenon.
The RISC-loading complex allows the loading of dsRNA fragments (generated by Dicer) to be loaded onto Argonaute 2 (with the help of TRBP) as part of the RNA interference pathway.
The RISC-loading complex involving the endonuclease Dicer, TRBP and Argonaute 2, the catalytic centre of RISC. This complex allows the loading of dsRNA fragments, generated by Dicer, to be loaded on to Argonaute 2 as part of the RNA interference pathway.
Diagram of RISC activity with miRNAs.
RNA-induced transcriptional silencing
RNA-induced transcriptional silencing (RITS) is a form of RNA interference by which short RNA molecules – such as small interfering RNA (siRNA) – trigger the downregulation of transcription of a particular gene or genomic region. This is usually accomplished by posttranslational modification of histone tails (e.g. methylation of lysine 9 of histone H3) which target the genomic region for heterochromatin formation. The protein complex that binds to siRNAs and interacts with the methylated lysine 9 residue of histones H3 is the RITS complex.
RITS was discovered in the fission yeastSchizosaccharomyces pombe, and has been shown to be involved in the initiation and spreading of heterochromatin in the mating-type region and in centromere formation. The RITS complex in S. pombe contains at least a piwi domain-containing RNase H-like argonaute, a chromodomain protein Chp1, and an argonaute interacting protein Tas3 which can also bind to Chp1, while heterochromatin formation has been shown to require at least argonaute and an RNA-dependent RNA polymerase. Loss of these genes in S. pombe results in abnormal heterochromatin organization and impairment of centromere function, resulting in lagging chromosomes on anaphase during cell division.(W)
RNA interference
RNA interference (RNAi) is a biological process in which RNA molecules inhibit gene expression or translation, by neutralizing targeted mRNA molecules. Historically, RNAi was known by other names, including co-suppression, post-transcriptional gene silencing (PTGS), and quelling. The detailed study of each of these seemingly different processes elucidated that the identity of these phenomena were all actually RNAi. Andrew Fire and Craig C. Mello shared the 2006 Nobel Prize in Physiology or Medicine for their work on RNA interference in the nematode worm Caenorhabditis elegans, which they published in 1998. Since the discovery of RNAi and its regulatory potentials, it has become evident that RNAi has immense potential in suppression of desired genes. RNAi is now known as precise, efficient, stable and better than antisense therapy for gene suppression. However, antisense RNA produced intracellularly by an expression vector may be developed and find utility as novel therapeutic agents.
Two types of small ribonucleic acid (RNA) molecules – microRNA (miRNA) and small interfering RNA (siRNA) – are central to RNA interference. RNAs are the direct products of genes, and these small RNAs can direct enzyme complexes to degrade messenger RNA (mRNA) molecules and thus decrease their activity by preventing translation, via post-transcriptional gene silencing. Moreover, transcription can be inhibited via the pre-transcriptional silencing mechanism of RNA interference, through which an enzyme complex catalyzes DNA methylation at genomic positions complementary to complexed siRNA or miRNA. RNA interference has an important role in defending cells against parasitic nucleotide sequences – viruses and transposons. It also influences development. (W)
Lentiviral delivery of designed shRNAs and the mechanism of RNA interference in mammalian cells.
The dicer protein from Giardia intestinalis, which catalyzes the cleavage of dsRNA to siRNAs. The RNase domains are colored green, the PAZ domain yellow, the platform domain red, and the connector helix blue.
One molecule of the Dicer-homolog protein from Giardia intestinalis, colored by domain (PAZ domain yellow, platform domain red, connector helix blue, RNase and bridge domains green). Dicer is an RNase that cleaves long double-stranded RNA molecules into short interfering RNAs (siRNAs) as a first step in the RNA interference response, and also initiates the formation of the RNA-induced silencing complex (RISC).
Left: (Image:1u04-argonaute.png) A full-length argonaute protein from the archaea species Pyrococcus furiosus. Right: (Right:Image:1ytu_argonaute_dsrna.png) The PIWI domain of an argonaute protein in complex with double-stranded RNA. The base-stacking interaction between the 5' base on the guide strand and a conserved tyrosine residue (light blue) is highlighted; the stabilizing divalent cation (magnesium) is shown as a gray sphere.
small RNA Biogenesis: primary miRNAs (pri-miRNAs) are transcribed in the nucleus and fold back onto themselves as hairpins that are then trimmed in the nucleus by a microprocessor complex to form a ~60-70nt hairpin pre-RNA. This pre-miRNA is transported through the nuclear pore complex (NPC) into the cytoplasm, where Dicer further trims it to a ~20nt miRNA duplex (pre-siRNAs also enter the pathway at this step). This duplex is then loaded into Ago to form the “pre-RISC(RNA induced silencing complex)” and the passenger strand is released to form active RISC.
Overview of RNA interference. The dicer enzymes produce siRNA from double-stranded RNA and mature miRNA from precursor miRNA. miRNA or siRNA is bound to an argonaute enzyme and an effector complex is formed, either a RISC (RNA-induced silencing complex) or RITS (RNA-induced transcriptional silencing) complex. RITS affects the rate of transcription by histone and DNA methylation, whereas RISC degrades mRNA to prevent it from being translated.
Illustration of the major differences between plant and animal gene silencing. Natively expressed microRNA or exogenous small interfering RNA is processed by dicer and integrated into the RISC complex, which mediates gene silencing.
microRNA biogenesis and action.
Timeline of RNAi's use in medicine between 1995-2017.
This enzyme belongs to the family of ligases, specifically those forming phosphoric-ester bonds. The systematic name of this enzyme class is poly(ribonucleotide):poly(ribonucleotide) ligase (AMP-forming). Other names in common use include polyribonucleotide synthase (ATP), RNA ligase, polyribonucleotide ligase, and ribonucleic ligase. (W)
RNA polymerase
In molecular biology,RNA polymerase (abbreviated RNAP or RNApol, and officially DNA-directed RNA polymerase), is an enzyme that synthesizes RNA from a DNA template.
Using the enzyme helicase, RNAP locally opens the double-stranded DNA so that one strand of the exposed nucleotides can be used as a template for the synthesis of RNA, a process called transcription. A transcription factor and its associated transcription mediator complex must be attached to a DNA binding site called a promoter region before RNAP can initiate the DNA unwinding at that position. RNAP not only initiates RNA transcription, it also guides the nucleotides into position, facilitates attachment and elongation, has intrinsic proofreading and replacement capabilities, and termination recognition capability. In eukaryotes, RNAP can build chains as long as 2.4 million nucleotides.
RNAP produces RNA that, functionally, is either for protein coding, i.e. messenger RNA (mRNA); or non-coding (so-called "RNA genes"). At least four functional types of RNA genes exist:
RNA polymerase is essential to life, and is found in all living organisms and many viruses. Depending on the organism, a RNA polymerase can be a protein complex (multi-subunit RNAP) or only consist of one subunit (single-subunit RNAP, ssRNAP), each representing an independent lineage. The former is found in bacteria,archaea, and eukaryotes alike, sharing a similar core structure and mechanism. The latter is found in phages as well as eukaryotic chloroplasts and mitochondria, and is related to modern DNA polymerases. Eukaryotic and archaeal RNAPs have more subunits than bacterial ones do, and are controlled differently.
Bacteria and archaea only have one RNA polymerase. Eukaryotes have multiple types of nuclear RNAP, each responsible for synthesis of a distinct subset of RNA:
RNA polymerase I synthesizes a pre-rRNA 45S (35S in yeast), which matures and will form the major RNA sections of the ribosome.
RNA polymerase IV and V found in plants are less understood; they make siRNA. In addition to the ssRNAPs, chloroplasts also encode and use a bacteria-like RNAP. (W)
RNA polymerase hetero27mer + DNA helix + Zn (l.blue), Human.
RNA polymerase (purple) unwinding the DNA double helix and uses one strand (darker orange) as a template to create the single-stranded messenger RNA (green)
RNA polymerase (purple) is a complex enzyme at the heart of transcription. During this process, the enzyme unwinds the DNA double helix and uses one strand (darker orange) as a template to create the single-stranded messenger RNA (green), later used by ribosomes for protein synthesis. From the RNA polymerase II elongation complex of Saccharomyces cerevisiae (PDB Structure 1i6h) as seen in http://pdb101.rcsb.org/learn/flyers-posters-and-other-resources/calendar/2019-calendar-what-is-a-protein. (W)
RNA polymerase III
In eukaryote cells, RNA polymerase III (also called Pol III) transcribesDNA to synthesize ribosomal 5S rRNA,tRNA and other small RNAs.
The genes transcribed by RNA Pol III fall in the category of "housekeeping" genes whose expression is required in all cell types and most environmental conditions. Therefore, the regulation of Pol III transcription is primarily tied to the regulation of cell growth and the cell cycle, thus requiring fewer regulatory proteins than RNA polymerase II. Under stress conditions however, the protein Maf1 represses Pol III activity. Rapamycin is another Pol III inhibitor via its direct target TOR. (W)
RNA-Seq
RNA-Seq (named as an abbreviation of "RNA sequencing") is a particular technology-based sequencing technique which uses next-generation sequencing (NGS) to reveal the presence and quantity of RNA in a biological sample at a given moment, analyzing the continuously changing cellular transcriptome.(W)
Summary of RNA-Seq. Within the organism, genes are transcribed and (in an eukaryotic organism) spliced to produce mature mRNA transcripts (red). The mRNA is extracted from the organism, fragmented and copied into stable ds-cDNA (blue). The ds-cDNA is sequenced using high-throughput, short-read sequencing methods. These sequences can then be aligned to a reference genome sequence to reconstruct which genome regions were being transcribed. This data can be used to annotate where expressed genes are, their relative expression levels, and any alternative splice variants.
Within the organisms, genes are transcribed and spliced (in eukaryotes) to produce mature mRNA transcripts (red). The mRNA is extracted from the organism, fragmented and copied into stable ds-cDNA (blue). The ds-cDNA is sequenced using high-throughput, short-read sequencing methods. These sequences can then be aligned to a reference genome sequence to reconstruct which genome regions were being transcribed. This data can be used to annotate where expressed genes are, their relative expression levels, and any alternative splice variants.
Overview of a typical RNA-Seq experimental workflow..
"RNA-seq data generation. A typical RNA-seq experimental workflow involves the isolation of RNA from samples of interest, generation of sequencing libraries, use of a high-throughput sequencer to produce hundreds of millions of short paired-end reads, alignment of reads against a reference genome or transcriptome, and downstream analysis for expression estimation, differential expression, transcript isoform discovery, and other applications. Refer to S1 Table, S3 Table, and S7 Table for more details on the concepts depicted in this figure." Image taken from Figure 2 in Griffith, Malachi; Walker, Jason R.; Spies, Nicholas C.; Ainscough, Benjamin J.; Griffith, Obi L. (2015). "Informatics for RNA Sequencing: A Web Resource for Analysis on the Cloud". PLOS Computational Biology. 11 (8): e1004393. doi:10.1371/journal.pcbi.1004393. ISSN 1553-7358.
Introns are removed and exons joined together in the process of RNA splicing.
RNA vaccine
An RNA vaccine or mRNA (messenger RNA) vaccine is a new type of vaccine that inserts fragments of viral mRNA into human cells, which are reprogrammed to produce pathogenantigens (e.g. viral protein spikes or cancer antigens), which then stimulate an adaptive immune response against the pathogen. The mRNA molecule is usually held in a drug delivery vehicle, such as lipid nanoparticles, to protect the fragile mRNA strands, and aid their absorption into the human cells. The advantages of RNA vaccines over traditional protein vaccines include production speed and cost, and the induction of cellular immunity as well as humoral immunity. The fragility of the mRNA molecule requires cold chain distribution and low temperature storage, and may impair the effective efficacy due to inadequate dosage.
Up until November 2020, no mRNA vaccine, drug, or technology platform, had ever been approved for use in humans, and before 2020, mRNA was only considered a theoretical or experimental candidate for human use. As of November 2020, there were two novel mRNA vaccines awaiting emergency use authorization as COVID-19 vaccines (having completed the 8-week required period post final human trials) – MRNA-1273 from Moderna, and BNT162b2 from a BioNTech/Pfizer partnership. Global regulators had to balance a lack of medium to longer-term data on potential side-effects from novel mRNA COVID-19 vaccines, with the urgent need to address the global coronavirus pandemic, for which the faster production capability of mRNA vaccines is valuable. (W)
The International Committee on Taxonomy of Viruses (ICTV) classifies RNA viruses as those that belong to Group III, Group IV or Group V of the Baltimore classification system of classifying viruses and does not consider viruses with DNA intermediates in their life cycle as RNA viruses. Viruses with RNA as their genetic material which also include DNA intermediates in their replication cycle are called retroviruses, and comprise Group VI of the Baltimore classification. Notable human retroviruses include HIV-1 and HIV-2, the cause of the disease AIDS.(W)
Taxonomy and replication strategies of different types of RNA viruses. (W).
Structure of the reovirus virion.
The T=1 inner capsid encloses the 10 double-stranded RNA gene segments and is covered by a T=13 outer capsid. Twelve spikes project from the core through the outer capsid. Gene segments are classified as large (L), medium (M), or small (S) based on relative electrophoretic mobilities. Viral capsid proteins are labeled. Nine of the 10 reovirus gene segments code for a single protein; the exception is the S1 gene, which codes for both the (sigma)1 attachment protein and the (sigma)1s nonstructural protein in overlapping reading frames. Viral proteins are named with the Greek letters (lambda), (mu), and (sigma), corresponding to the size classes (L, M, and S) of their respective gene segments. (W)
RNase MRP
RNase MRP (also called RMRP) is an enzymatically active ribonucleoprotein with two distinct roles in eukaryotes. RNAse MRP stands for RNAse for mitochondrial RNA processing. In mitochondria it plays a direct role in the initiation of mitochondrial DNA replication. In the nucleus it is involved in precursor rRNA processing, where it cleaves the internal transcribed spacer 1 between 18S and 5.8S rRNAs. Despite distinct functions, RNase MRP has been shown to be evolutionarily related to RNase P. Like eukaryotic RNase P, RNase MRP is not catalytically active without associated protein subunits.
Mutations in the RNA component of RNase MRP cause cartilage–hair hypoplasia, a pleiotropic human disease. Responsible for this disease is a mutation in the RNase MRP RNA gene (RMRP), a non-coding RNA gene. RMRP was the first non-coding nuclear RNA gene found to cause disease. (W)
Diagram of RNase MRP role in cell cycle control. Rnase MRP degrades CLB2 mRNA. CLB2 mRNA is processed to create an uncapped RNA transcript. This transcript is then degraded by Xrn1 5'-3' exoribonuclease. Defective RNase MRP results in increased CLB2 mRNA and protein. Maintained CLB2 protein levels allows Cdc28 (a cyclin-dependent kinase) to remain active and inhibit the end of mitosis.
RNase R
RNase R, or Ribonuclease R, is a 3'-->5' exoribonuclease, which belongs to the RNase II superfamily ,a group of enzymes that hydrolyze RNA in the 3' - 5' direction. RNase R has been shown to be involved in selective mRNA degradation, particularly of non stop mRNAs in bacteria. RNase R has homologues in many other organisms.
When a part of another larger protein has a domain that is very similar to RNase R, this is called an RNase R domain.(W)
s
saccharide
The term [scccaride] is most common in biochemistry, where it is a synonym of saccharide, a group that includes sugars,starch, and cellulose. The saccharides are divided into four chemical groups: monosaccharides, disaccharides,oligosaccharides, and polysaccharides. Monosaccharides and disaccharides, the smallest (lower molecular weight) carbohydrates, are commonly referred to as sugars. The word saccharide comes from the Greek word σάκχαρον (sákkharon), meaning "sugar". While the scientific nomenclature of carbohydrates is complex, the names of the monosaccharides and disaccharides very often end in the suffix -ose, as in the monosaccharides fructose (fruit sugar) and glucose (starch sugar) and the disaccharides sucrose (cane or beet sugar) and lactose (milk sugar). (W)
Monosaccharides are the simplest form of carbohydrates with only one simple sugar. They essentially contain an aldehyde or ketone group in their structure. The presence of an aldehyde group in a monosaccharide is indicated by the prefix aldo-. Similarly, a ketone group is denoted by the prefix keto-. Examples of monosaccharides are the hexoses,glucose,fructose,Trioses,Tetroses,Heptoses, galactose, pentoses, ribose, and deoxyribose. Consumed fructose and glucose have different rates of gastric emptying, are differentially absorbed and have different metabolic fates, providing multiple opportunities for 2 different saccharides to differentially affect food intake. Most saccharides eventually provide fuel for cellular respiration.
Disaccharides are formed when two monosaccharides, or two single simple sugars, form a bond with removal of water. They can be hydrolyzed to yield their saccharin building blocks by boiling with dilute acid or reacting them with appropriate enzymes. Examples of disaccharides include sucrose,maltose, and lactose.
Polysaccharides are polymerized monosaccharides, or complex carbohydrates. They have multiple simple sugars. Examples are starch,cellulose, and glycogen. They are generally large and often have a complex branched connectivity. Because of their size, polysaccharides are not water-soluble, but their many hydroxy groups become hydrated individually when exposed to water, and some polysaccharides form thick colloidal dispersions when heated in water. Shorter polysaccharides, with 3 - 10 monomers, are called oligosaccharides. A fluorescent indicator-displacement molecular imprinting sensor was developed for discriminating saccharides. It successfully discriminated three brands of orange juice beverage. The change in fluorescence intensity of the sensing films resulting is directly related to the saccharide concentration.
Sanger sequencingSanger sequencing is a method of DNA sequencing based on the selective incorporation of chain-terminating dideoxynucleotides by DNA polymerase during in vitroDNA replication. After first being developed by Frederick Sanger and colleagues in 1977, it became the most widely used sequencing method for approximately 40 years. It was first commercialized by Applied Biosystems in 1986. More recently, higher volume Sanger sequencing has been replaced by "Next-Gen" sequencing methods, especially for large-scale, automated genome analyses. However, the Sanger method remains in wide use, for smaller-scale projects, and for validation of Next-Gen results. It still has the advantage over short-read sequencing technologies (like Illumina) in that it can produce DNA sequence reads of > 500 nucleotides. (W)
The Sanger (chain-termination) method for DNA sequencing.
The Sanger (chain-termination) method for DNA sequencing. (1) A primer is annealed to a sequence, (2) Reagents are added to the primer and template, including: DNA polymerase, dNTPs, and a small amount of all four dideoxynucleotides (ddNTPs) labeled with fluorophores. During primer elongation, the random insertion of a ddNTP instead of a dNTP terminates synthesis of the chain because DNA polymerase cannot react with the missing hydroxyl. This produces all possible lengths of chains. (3) The products are separated on a single lane capillary gel, where the resulting bands are read by a imaging system. (4) This produces several hundred thousand nucleotides a day, data which require storage and subsequent computational analysis.
DNA fragments are labelled with a radioactive or fluorescent tag on the primer (1), in the new DNA strand with a labeled dNTP, or with a labeled ddNTP.
Part of a radioactively labelled sequencing gel.
second messenger system
Second messengers are intracellular signaling molecules released by the cell in response to exposure to extracellular signaling molecules—the first messengers. (Intracellular signals, a non-local form or cell signaling, encompassing both first messengers and second messengers, are classified as juxtacrine, paracrine, and endocrine depending on the range of the signal.) Second messengers trigger physiological changes at cellular level such as proliferation, differentiation, migration, survival, apoptosis and depolarization.
Examples of second messenger molecules include cyclic AMP, cyclic GMP, inositol trisphosphate, diacylglycerol, and calcium. First messengers are extracellular factors, often hormones or neurotransmitters, such as epinephrine, growth hormone, and serotonin. Because peptide hormones and neurotransmitters typically are biochemically hydrophilic molecules, these first messengers may not physically cross the phospholipid bilayer to initiate changes within the cell directly—unlike steroid hormones, which usually do. This functional limitation requires the cell to have signal transduction mechanisms to transduce first messenger into second messengers, so that the extracellular signal may be propagated intracellularly. An important feature of the second messenger signaling system is that second messengers may be coupled downstream to multi-cyclic kinase cascades to greatly amplify the strength of the original first messenger signal. For example, RasGTP signals link with the mitogen activated protein kinase (MAPK) cascade to amplify the allosteric activation of proliferative transcription factors such as Myc and CREB.(W)
Just as higher forms of life have evolved a complex mitotic apparatus to partition duplicated DNA during cell division,bacteria require a specialized apparatus to partition their duplicated DNA. In bacteria, segrosomes perform the function similar to that performed by mitotic spindle. Therefore, segrosomes can be thought of as minimalist spindles.
Segrosomes are usually composed of three basic components- the DNA (plasmid or chromosome) that needs to be segregated into daughter cells, a motor protein that provides the necessary physical forces for accomplishing the segregation and a DNA binding protein that connects the DNA and the motor protein, to form the complete segrosome complex. (W)
self-assembly
Self-assembly is a process in which a disordered system of pre-existing components forms an organized structure or pattern as a consequence of specific, local interactions among the components themselves, without external direction. When the constitutive components are molecules, the process is termed molecular self-assembly.
Self-assembly can be classified as either static or dynamic. In static self-assembly, the ordered state forms as a system approaches equilibrium, reducing its free energy. However, in dynamic self-assembly, patterns of pre-existing components organized by specific local interactions are not commonly described as "self-assembled" by scientists in the associated disciplines. These structures are better described as "self-organized", although these terms are often used interchangeably. (W)
Self-assembly of lipids (a), proteins (b), and (c) SDS-cyclodextrin complexes. SDS is a surfactant with a hydrocarbon tail (yellow) and a SO4 head (blue and red), while cyclodextrin is a saccharide ring (green C and red O atoms).
📥 Self-assembly (W)
self-replicationSelf-replication is any behavior of a dynamical system that yields construction of an identical or similar copy of itself.Biological cells, given suitable environments, reproduce by cell division. During cell division, DNA is replicated and can be transmitted to offspring during reproduction.Biological viruses can replicate, but only by commandeering the reproductive machinery of cells through a process of infection. Harmful prion proteins can replicate by converting normal proteins into rogue forms. Computer viruses reproduce using the hardware and software already present on computers. Self-replication in robotics has been an area of research and a subject of interest in science fiction. Any self-replicating mechanism which does not make a perfect copy (mutation) will experience genetic variation and will create variants of itself. These variants will be subject to natural selection, since some will be better at surviving in their current environment than others and will out-breed them. (W)
senescence
Senescence or biologicalaging is the gradual deterioration of functional characteristics. The word senescence can refer either to cellular senescence or to senescence of the whole organism. Organismal senescence involves an increase in death rates and/or a decrease in fecundity with increasing age, at least in the latter part of an organism's life cycle.
Environmental factors may affect aging, for example, overexposure to ultraviolet radiation accelerates skin aging. Different parts of the body may age at different rates. Two organisms of the same species can also age at different rates, making biological aging and chronological aging distinct concepts. (W)
sense (molecular biology)
In molecular biology and genetics, the sense of a nucleic acid molecule, particularly of a strand of DNA or RNA, refers to the nature of the roles of the strand and its complement in specifying a sequence of amino acids. Depending on the context, sense may have slightly different meanings. For example, DNA is positive-sense if an RNA version of the same sequence is translated or translatable into protein, negative-sense if not. (W)
sequence (biology)
A sequence in biology is the one-dimensional ordering of monomers,covalently linked within a biopolymer; it is also referred to as the primary structure of a biological macromolecule. While it can refer to many different molecules, the term sequence is most often used to refer to a DNA sequence.
Sequencing by hybridization is a class of methods for determining the order in which nucleotides occur on a strand of DNA. Typically used for looking for small changes relative to a known DNA sequence. The binding of one strand of DNA to its complementary strand in the DNA double-helix (known as hybridization) is sensitive to even single-base mismatches when the hybrid region is short or if specialized mismatch detection proteins are present. This is exploited in a variety of ways, most notably via DNA chips or microarrays with thousands to billions of synthetic oligonucleotides found in a genome of interest plus many known variations or even all possible single-base variations.
The type of sequencing by hybridization described above has largely been displaced by other methods, including sequencing by synthesis, and sequencing by ligation (as well as pore-based methods). However hybridization of oligonucleotides is still used in some sequencing schemes, including hybridization-assisted pore-based sequencing, and reversible hybridization. (W)
sequencing by ligationSequencing by ligation is a DNA sequencing method that uses the enzyme DNA ligase to identify the nucleotide present at a given position in a DNA sequence. Unlike most currently popular DNA sequencing methods, this method does not use a DNA polymerase to create a second strand. Instead, the mismatch sensitivity of a DNA ligase enzyme is used to determine the underlying sequence of the target DNA molecule.(W)
serial analysis of gene expression (SAGE)
Serial Analysis of Gene Expression (SAGE) is a transcriptomic technique used by molecular biologists to produce a snapshot of the messenger RNA population in a sample of interest in the form of small tags that correspond to fragments of those transcripts. Several variants have been developed since, most notably a more robust version, LongSAGE, RL-SAGE and the most recent SuperSAGE. Many of these have improved the technique with the capture of longer tags, enabling more confident identification of a source gene. (W)
Summary of SAGE. Within the organisms, genes are transcribed and spliced (in eukaryotes) to produce mature mRNA transcripts (red). The mRNA is extracted from the organism, and reverse transcriptase is used to copy the mRNA into stable double-stranded–cDNA (ds-cDNA; blue). In SAGE, the ds-cDNA is digested by restriction enzymes (at location 'X' and 'X'+11) to produce 11-nucleotide 'tag' fragments. These tags are concatenated and sequenced using long-read Sanger sequencing (different shades of blue indicate tags from different genes). The sequences are deconvoluted to find the frequency of each tag. The tag frequency can be used to report on transcription of the gene that the tag came from.
shelterin (telesome)
Shelterin (also called telosome) is a protein complex known to protect telomeres in many eukaryotes from DNA repair mechanisms, as well as to regulate telomerase activity. In mammals and other vertebrates, telomeric DNA consists of repeating double-stranded 5'-TTAGGG-3' (G-strand) sequences (2-15 kilobases in humans) along with the 3'-AATCCC-5' (C-strand) complement, ending with a 50-400 nucleotide 3' (G-strand) overhang. Much of the final double-stranded portion of the telomere forms a T-loop (Telomere-loop) that is invaded by the 3' (G-strand) overhang to form a small D-loop (Displacement-loop).
Schematics of the arrangement of proteins in the telosome/shelterin complex.
Shelterin co-ordinates the T-loop formation of telomeres.
short hairpin RNA
A short hairpin RNA or small hairpin RNA (shRNA/Hairpin Vector) is an artificial RNA molecule with a tight hairpin turn that can be used to silence target gene expression via RNA interference (RNAi). Expression of shRNA in cells is typically accomplished by delivery of plasmids or through viral or bacterial vectors. shRNA is an advantageous mediator of RNAi in that it has a relatively low rate of degradation and turnover. However, it requires use of an expression vector, which has the potential to cause side effects in medicinal applications.
The promoter choice is essential to achieve robust shRNA expression. At first, polymerase III promoters such as U6 and H1 were used; however, these promoters lack spatial and temporal control. As such, there has been a shift to using polymerase II promoters to regulate shRNA expression. (W)
Lentiviral delivery of shRNA and the mechanism of RNA interference in mammalian cells.
Lentiviral delivery of shRNA expression construct for stable integration and expresion of shRNA. ShRNA processing and inhibitory mechanisms.
The dicer protein from Giardia intestinalis. One molecule of the Dicer-homolog protein from Giardia intestinalis, colored by domain (PAZ domain yellow, platform domain red, connector helix blue, RNase and bridge domains green). Dicer is an RNase that cleaves long double-stranded RNA molecules into short interfering RNAs (siRNAs) as a first step in the RNA interference response, and also initiates the formation of the RNA-induced silencing complex (RISC). .
The internal regions of SINEs originate from tRNA and remain highly conserved, suggesting positive pressure to preserve structure and function of SINEs. While SINEs are present in many species of vertebrates and invertebrates, SINEs are often lineage specific, making them useful markers of divergent evolution between species. Copy number variation and mutations in the SINE sequence make it possible to construct phylogenies based on differences in SINEs between species. SINEs are also implicated in certain types of genetic disease in humans and other eukaryotes.
In essence, short interspersed nuclear elements are genetic parasites which have evolved very early in the history of eukaryotes to utilize protein machinery within the organism as well as to co-opt the machinery from similarly parasitic genomic elements. The simplicity of these elements make them incredibly successful at persisting and amplifying (through retrotransposition) within the genomes of eukaryotes. These "parasites" which have become ubiquitous in genomes can be very deleterious to organisms as discussed below. However, eukaryotes have been able to integrate short-interspersed nuclear elements into different signaling, metabolic and regulatory pathways and have become a great source of genetic variability. They seem to play a particularly important role in the regulation of gene expression and the creation of RNA genes. This regulation extends to chromatin re-organization and the regulation of genomic architecture; furthermore, the different lineages, mutations, and activity among eukaryotes make short-interspersed nuclear elements an incredible useful tool in phylogenetic analysis. (W)
Genetic structure of human and murine LINE1 and SINEs.
side chain
In organic chemistry and biochemistry, a side chain is a chemical group that is attached to a core part of the molecule called the "main chain" or backbone. The side chain is a hydrocarbon branching element of a molecule that is attached to a larger hydrocarbon backbone. It is one factor in determining a molecule's properties and reactivity. A side chain is also known as a pendant chain, but a pendant group (side group) has a different definition. (W)
Table of amino acids.
siDNASignal interfering DNA (siDNA) is a class of short modified double stranded DNA molecules, 8–64 base pairs in length. siDNA molecules are capable of inhibiting DNA repair activities by interfering with multiple repair pathways. These molecules are known to act by mimicking DNA breaks and interfering with recognition and repair of DNA damage induced on chromosomes by irradiation or genotoxic products.
Dbait
Dbait is a specific siDNA molecule that has been shown to mimic signalling of double-stranded DNA breaks (DSBs) in vivo. Currently, Dbait is the only type of siDNA molecule having been reviewed. (W)
The signal recognition particle RNA, (also known as 7SL, 6S, ffs, or 4.5S RNA) is part of the signal recognition particle (SRP) ribonucleoprotein complex. SRP recognizes the signal peptide and binds to the ribosome, halting protein synthesis. SRP-receptor is a protein that is embedded in a membrane, and which contains a transmembrane pore. When the SRP-ribosome complex binds to SRP-receptor, SRP releases the ribosome and drifts away. The ribosome resumes protein synthesis, but now the protein is moving through the SRP-receptor transmembrane pore.
In this way SRP directs the movement of proteins within the cell to bind with a transmembrane pore which allows the protein to cross the membrane to where it is needed. The RNA and protein components of this complex are highly conserved but do vary between the different kingdoms of life.
The common SINE family Alu probably originated from a 7SL RNA gene after deletion of a central sequence.
The eukaryotic SRP consists of a 300-nucleotide 7S RNA and six proteins: SRPs 72, 68, 54, 19, 14, and 9. Archaeal SRP consists of a 7S RNA and homologues of the eukaryotic SRP19 and SRP54 proteins. Eukaryotic and archaeal 7S RNAs have very similar secondary structures. (W)
Secondary structure of the human SRP RNA. Helices are numbered from 2 to 8. Helical sections in gray are named with lower case letters. Residues are numbered in increments of ten. The 5′- and 3′-ends are indicated. Highlighted are the two hinges and the small (Alu) and large (S, "specific") domain of the SRP RNA.
The classical function of SRP in translation-translocation. A membrane separates the cytosol from the endoplasmic reticulum. A ribosome (light gray with A, P, and E sites) synthesizes a protein with a signal peptide (green) encoded by messenger RNA (indicated by a line with 5′- and 3′-ends). The elongated SRP (blue), with its large (LD) and small (SD) domains, forms a complex with the membrane-resident SRP receptor (SR). When SRP separates, the protein crosses the membrane through a channel or translocon. The signal peptide may be removed by signal peptide peptidase (SP) and the protein modified by oligosaccharyl transferase (OT).
SRP RNA features and nomenclature. The human SRP RNA secondary structure is outlined in light gray, and the 5′- and 3′-ends are indicated. Conserved motifs are shown in dark gray. Helices are numbered from 1 to 12, helical sections are designated by lower case letters, and helix insertions by dotted numbers. Tertiary interactions between the apical loops of helices 3 and 4, and between helices 6 and 8 are indicated dotted lines.
signal transductionSignal transduction is the process by which a chemical or physical signal is transmitted through a cell as a series of molecular events, most commonly protein phosphorylation catalyzed by protein kinases, which ultimately results in a cellular response. Proteins responsible for detecting stimuli are generally termed receptors, although in some cases the term sensor is used. The changes elicited by ligand binding (or signal sensing) in a receptor give rise to a biochemical cascade, which is a chain of biochemical events known as a signaling pathway. (W)
Simplified representation of major signal transduction pathways in mammals.
3D Medical animation still showing signal transduction.
A signal transduction showing the transformation of a stimulus into a biochemical signal.
An overview of integrin-mediated signal transduction, adapted from Hehlgens et al. (2007).
How to read signal transduction diagrams, what does normal arow and flat head arrow means.
RNA polymerase, a DNA-dependent enzyme, transcribes the DNA sequences, called nucleotides, in the 3' to 5' direction while the complementary RNA is synthesized in the 5' to 3' direction. RNA is similar to DNA, except that RNA contains uracil, instead of thymine, which forms a base pair with adenine. An important region for the activity of gene repression and expression found in RNA is the 3' untranslated region. This is a region on the 3' terminus of RNA that will not be translated to protein but includes many regulatory regions.
Not much is yet known about silencers but scientists continue to study in hopes to classify more types, locations in the genome, and diseases associated with silencers. (W)
The 3' untranslated region of mRNA labeled 3' UTR. Normally about 700 nucleotides in human mRNA.
Diagramatic structure of a typical human protein coding mRNA including the untranslated regions (UTRs).It is drawn approximately to scale. The cap is only one modified base, average en:5' UTR length 170, en:3' UTR 700. Reproduced from http://commons.wikimedia.org/wiki/Image:MRNA_structure.png
DNA is transcribed into mRNA, introns are spliced during post-transcriptional regulation, and the remaining exons comprise the mRNA.
In the method, an oligonucleotide primer hybridizes to a complementary region along the nucleic acid to form a duplex, with the primer’s terminal 3’-end directly adjacent to the nucleotide base to be identified. Using a DNA polymerase, the oligonucleotide primer is enzymatically extended by a single base in the presence of all four nucleotide terminators; the nucleotide terminator complementary to the base in the template being interrogated is incorporated and identified. The presence of all four terminators suppresses misincorporation of non-complementary nucleotides. Many approaches can be taken for determining the identity of an incorporated terminator, including fluorescence labeling, mass labeling for mass spectrometry, isotope labeling, and tagging the base with a hapten and detecting chromogenically with an anti-hapten antibody-enzyme conjugate (e.g., via an ELISA format).
The method was invented by Philip Goelet, Michael Knapp, Richard Douglas and Stephen Anderson while working at the company Molecular Tool. This approach was designed for high-throughput SNP genotyping and was originally called "Genetic Bit Analysis" (GBA). Illumina, Inc. utilizes this method in their Infinium technology (http://www.illumina.com/technology/beadarray-technology/infinium-hd-assay.html) to measure DNA methylation levels in the human genome. (W)
single cell sequencingSingle cell sequencing examines the sequence information from individual cells with optimized next-generation sequencing (NGS) technologies, providing a higher resolution of cellular differences and a better understanding of the function of an individual cell in the context of its microenvironment. For example, in cancer, sequencing the DNA of individual cells can give information about mutations carried by small populations of cells. In development, sequencing the RNAs expressed by individual cells can give insight into the existence and behavior of different cell types. In microbial systems, a population of the same species can appear to be genetically clonal, but single-cell sequencing of RNA or epigenetic modifications can reveal cell-to-cell variability that may help populations rapidly adapt to survive in changing environments. (W)
single-nucleotide polymorphism
A single-nucleotide polymorphism (SNP; /snɪp/; plural /snɪps/) is a substitution of a single nucleotide at a specific position in the genome, that is present in a sufficiently large fraction of the population (e.g. 1% or more).
For example, at a specific base position in the human genome, the C nucleotide may appear in most individuals, but in a minority of individuals, the position is occupied by an A. This means that there is a SNP at this specific position, and the two possible nucleotide variations – C or A – are said to be the alleles for this specific position.
SNPs pinpoint differences in our susceptibility to a wide range of diseases (e.g. sickle-cell anemia,β-thalassemia and cystic fibrosis result from SNPs). The severity of illness and the way the body responds to treatments are also manifestations of genetic variations. For example, a single-base mutation in the APOE (apolipoprotein E) gene is associated with a lower risk for Alzheimer's disease.
A single-nucleotide variant (SNV) is a variation in a single nucleotide without any limitations of frequency. SNV differs from SNP because when an SNV is detected in a sample from one organism of a species the SNV could potentially be a SNP but this cannot be determined from only one organism. SNP however means the nucleotide varies in a species' population of organisms. SNVs may arise in somatic cells. A somatic single-nucleotide variation (e.g., caused by cancer) may also be called a single-nucleotide alteration. SNVs also commonly arise in molecular diagnostics. For example when designing PCR primers to detect viruses, the viral RNA or DNA in a single patient sample may contain SNVs. (W)
The upper DNA molecule differs from the lower DNA molecule at a single base-pair location (a C/A polymorphism).
Types of single-nucleotide polymorphism (SNPs).
sister chromatid exchange
Sister chromatid exchange (SCE) is the exchange of genetic material between two identical sister chromatids.
It was first discovered by using the Giemsa staining method on one chromatid belonging to the sister chromatid complex before anaphase in mitosis. The staining revealed that few segments were passed to the sister chromatid which were not dyed. The Giemsa staining was able to stain due to the presence of bromodeoxyuridine analogous base which was introduced to the desired chromatid.
The reason for the (SCE) is not known but it is required and used as a mutagenic testing of many products. Four to five sister chromatid exchanges per chromosome pair, per mitosis is in the normal distribution, while 14-100 exchanges is not normal and presents a danger to the organism. SCE is elevated in pathologies including Bloom syndrome, having recombination rates ~10-100 times above normal, depending on cell type. Frequent SCEs may also be related to formation of tumors.
Sister chromatid exchange has also been observed more frequently in B51(+) Behçet's disease. (W)
Metaphase spread of a cell line showing a ring chromosome (R) and several sister chromatid exchanges (SCEs), some of which are indicated by arrows.
Original figure legend: Metaphase chromosome spread from an induced cell transfected with GFP-ΔC1 BLM. A large ring chromosome is shown at the top of the spread. The SCEs are visualized with acridine orange staining..
Scheme of a sister chromatid exchange. The ends of the chromatids are reversed in the lower area.
small interfering RNASmall interfering RNA (siRNA), sometimes known as short interfering RNA or silencing RNA, is a class of double-stranded RNAnon-coding RNAmolecules, typically 20-27 base pairs in length, similar to miRNA, and operating within the RNA interference (RNAi) pathway. It interferes with the expression of specific genes with complementary nucleotide sequences by degrading mRNA after transcription, preventing translation(W)
Mediating RNA interference in cultured mammalian cells.
snRNA are always associated with a set of specific proteins, and the complexes are referred to as small nuclear ribonucleoproteins (snRNP, often pronounced "snurps"). Each snRNP particle is composed of a snRNA component and several snRNP-specific proteins (including Sm proteins, a family of nuclear proteins). The most common human snRNA components of these complexes are known, respectively, as: U1 spliceosomal RNA,U2 spliceosomal RNA,U4 spliceosomal RNA,U5 spliceosomal RNA, and U6 spliceosomal RNA. Their nomenclature derives from their high uridine content.
snRNAs were discovered by accident during a gel electrophoresis experiment in 1966. An unexpected type of RNA was found in the gel and investigated. Later analysis has shown that these RNA were high in uridylate and were established in the nucleus.
snRNAs and small nucleolar RNAs (snoRNAs) are not the same and is not a type of one another. Both are different and are a class under small RNAs. These are small RNA molecules that play an essential role in RNA biogenesis and guide chemical modifications of ribosomal RNAs (rRNAs) and other RNA genes (tRNA and snRNAs). They are located in the nucleolus and the Cajal bodies of eukaryotic cells (the major sites of RNA synthesis), where they are called scaRNAs (small Cajal body-specific RNAs). (W)
A comparison between major and minor splicing mechanisms.
Small RNA are <200 nt (nucleotide) in length, and are usually non-coding RNA molecules. RNA silencing is often a function of these molecules, with the most common and well-studied example being RNA interference (RNAi), in which endogenously expressed microRNA (miRNA) or exogenously derived small interfering RNA (siRNA) induces the degradation of complementarymessenger RNA. Other classes of small RNA have been identified, including piwi-interacting RNA (piRNA) and its subspecies repeat associated small interfering RNA (rasiRNA). Small RNA "is unable to induce RNAi alone, and to accomplish the task it must form the core of the RNA–protein complex termed the RNA-induced silencing complex (RISC), specifically with Argonaute protein". Also, mRNA is used in transcription.
Small RNA can be selected by MicroRNA sequencing, a technique that selects small RNA molecules, then sequences those of 21–25 bp size. The first analysis of small RNAs using miRNA-seq methods examined approximately 1.4 million small RNAs from the model plant Arabidopsis thaliana using Lynx Therapeutics' Massively Parallel Signature Sequencing (MPSS) sequencing platform. This study demonstrated the potential of novel, high-throughput sequencing technologies for the study of small RNAs, and it showed that genomes generate large numbers of small RNAs with plants as particularly rich sources of small RNAs. Later studies used other sequencing technologies, such as a study in C. elegans which identified 18 novel miRNA genes as well as a new class of nematode small RNAs termed 21U-RNAs. Another study comparing small RNA profiles of human cervical tumours and normal tissue, utilized the Illumina (company) Genome Analyzer to identify 64 novel human miRNA genes as well as 67 differentially expressed miRNAs. Applied Biosystems SOLiD sequencing platform has also been used to examine the prognostic value of miRNAs in detecting human breast cancer. Small RNA is useful for certain kinds of study because its molecules "do not need to be fragmented prior to library preparation".
SNP annotationSingle nucleotide polymorphism annotation (SNP annotation) is the process of predicting the effect or function of an individual SNP using SNP annotation tools. In SNP annotation the biological information is extracted, collected and displayed in a clear form amenable to query. SNP functional annotation is typically performed based on the available information on nucleic acid and protein sequences. (W)
Directed graph of relationships among SNP prediction webservers and their bioinformatics sources.
SNP genotypingSNP genotyping is the measurement of genetic variations of single nucleotide polymorphisms (SNPs) between members of a species. It is a form of genotyping, which is the measurement of more general genetic variation. SNPs are one of the most common types of genetic variation. A SNP is a single base pair mutation at a specific locus, usually consisting of two alleles (where the rare allele frequency is > 1%). SNPs are found to be involved in the etiology of many human diseases and are becoming of particular interest in pharmacogenetics. Because SNPs are conserved during evolution, they have been proposed as markers for use in quantitative trait loci (QTL) analysis and in association studies in place of microsatellites. The use of SNPs is being extended in the HapMap project, which aims to provide the minimal set of SNPs needed to genotype the human genome. SNPs can also provide a genetic fingerprint for use in identity testing. The increase of interest in SNPs has been reflected by the furious development of a diverse range of SNP genotyping methods. (W)
SNP-Dash-1updated.
sodium channelSodium channels are integral membrane proteins that form ion channels, conducting sodium ions (Na+) through a cell'splasma membrane. They belong to the superfamily of cation channels and can be classified according to the trigger that opens the channel for such ions, i.e. either a voltage-change ("voltage-gated", "voltage-sensitive", or "voltage-dependent" sodium channel; also called "VGSCs" or "Nav channel") or a binding of a substance (a ligand) to the channel (ligand-gated sodium channels).(W)
Diagram of a voltage-sensitive sodium channel α-subunit. G – glycosylation, P – phosphorylation, S – ion selectivity, I – inactivation. Positive (+) charges in S4 are important for transmembrane voltage sensing.
3D structure of the signaling domain, or N-terminal domain of the murine hedgehog protein.
Chromosome 7 (human). Ideogram of human chromosome. Chromosome 7 highlighted. G-band, 850 bphs (bands per haploid set). Black and gray: Giemsa positive. Red: Centromere. Light blue: Variable region. Dark blue: Stalk.
SOS boxSOS box is the region in the promoter of various genes to which the LexArepressor binds to repress the transcription of SOS-induced proteins. This occurs in the absence of DNA damage. In the presence of DNA damage the binding of LexA is inactivated by the RecAactivator. SOS boxes differ in DNA sequences and binding affinity towards LexA from organism to organism. Furthermore, SOS boxes may be present in a dual fashion, which indicates that more than one SOS box can be within the same promoter(W)
SOS response
The SOS response is a global response to DNA damage in which the cell cycle is arrested and DNA repair and mutagenesis is induced. The system involves the RecA protein (Rad51 in eukaryotes). The RecA protein, stimulated by single-stranded DNA, is involved in the inactivation of the repressor (LexA) of SOS response genes thereby inducing the response. It is an error-prone repair system that contributes significantly to DNA changes observed in a wide range of species.(W)
E. coli SOS System: DNA can be damaged by cross-linking agents, UV irradiation, alkylating agents, etc. Once damaged, RecA, a LexA protease, senses that damaged protein and becomes activated by removing its repressor. Once the LexA dimer repressor is removed, the expression of LexA operon is autoregulatory. In addition to being a LexA protease, the RecA protein also catalyzes a few novel DNA reactions such as annealing of single-stranded DNA and transfer of strands. The SOS system has enhanced DNA-repair capacity, including excision and post-replication repair, enhanced mutagenesis, prophage induction. The system can also inhibit cell division and cell respiration.
Overview of the use of the SOS response for genotoxicity testing.
The SOS response inhibits septum formation until bacterial DNA can be repaired and is observable as filamentation when cells are examined by microscopy (top right of image).
Southern blot
A Southern blot is a method used in molecular biologyfor detection of a specific DNA sequence in DNA samples. Southern blotting combines transfer of electrophoresis-separated DNA fragments to a filter membrane and subsequent fragment detection by probe hybridization.
Agarose gel. Title Recombinant DNA: Southern Blot Description A gel envelope being placed on a test pad, in a laboratory setting. Visible also are the rubber-gloved hands of scientists, a glass sheet and a white paper covering. They are preparing for the southern blot technique, now used in recombinant DNA technology. These new technologies have revolutionized the way scientists can look at the detail of cellular molecules. Topics/Categories Science and Technology -- Genetics Type Color, Photo Source National Cancer Institute.
Southernblot Aufbau.
Tray with a stack consisting top down of a weight, paper towels, membrane of nitrocellulose or nylon, gel, salt solution and a slab of glass.
Southern blot membrane after hybridization and rinsing.
Southern blot agarose gel under ultraviolet illumination.
spliceosome
A spliceosome is a large and complex molecular machine found primarily within the nucleus of eukaryotic cells. The spliceosome is assembled from small nuclear RNAs (snRNA) and approximately 80 proteins. The spliceosome removes introns from a transcribedpre-mRNA, a type of primary transcript. This process is generally referred to as splicing. An analogy is a film editor, who selectively cuts out irrelevant or incorrect material (equivalent to the introns) from the initial film and sends the cleaned-up version to the director for the final cut. (W)
Start codon (blue circle) of the human mitochondrial DNA MT-ATP6 gene. For each nucleotide triplet (square brackets), the corresponding amino acid is given (one-letter code), either in the +1 reading frame for MT-ATP8 (in red) or in the +3 frame for MT-ATP6 (in blue). In this genomic region, the two genes overlap.
The human genes MT-ATP8 and MT-ATP6 located in the mitochondrial DNA and coding for the ATP synthase F0 subunits 8 and 6 overlap on 46 nucleotides. The DNA sequence of this region of the human mitochondrial genome is given in black (positions 8,525 to 8,580 in the sequence accession NC_012920). There are three possible reading frames in the 5' -> 3' forward direction, starting on the first (+1), second (+2) and third position (+3). For each nucleotide triplet (square brackets), the corresponding amino acid is given (one-letter code), either in the +1 frame for MT-ATP8 (in red) or in the +3 frame for MT-ATP6 (in blue). The MT-ATP8 genes terminates with the TAG stop codon (red dot) in the +1 frame. The MT-ATP6 gene starts with the ATG codon (blue circle for the M amino acid) in the +3 frame. Forteen sense codons do overlap for the two genes. As both genes use different ORF, the two protein sequences are different in the overlap region. (W)
The steroid core structure is typically composed of seventeen carbon atoms, bonded in four "fused" rings: three six-member cyclohexane rings (rings A, B and C in the first illustration) and one five-member cyclopentane ring (the D ring). Steroids vary by the functional groups attached to this four-ring core and by the oxidation state of the rings. Sterols are forms of steroids with a hydroxy group at position three and a skeleton derived from cholestane. Steroids can also be more radically modified, such as by changes to the ring structure, for example, cutting one of the rings. Cutting Ring B produces secosteroids one of which is vitamin D3.
Structure of cholestane, a steroid with 27 carbon atoms. Its core ring system (ABCD), composed of 17 carbon atoms, is shown with IUPAC-approved ring lettering and atom numbering.
Space-filling representation.
Ball-and-stick representation.
5α-dihydroprogesterone (5α-DHP), a steroid. The shape of the four rings of most steroids is illustrated (carbon atoms in black, oxygens in red and hydrogens in grey). The nonpolar "slab" of hydrocarbon in the middle (grey, black) and the polar groups at opposing ends (red) are common features of natural steroids. 5α-DHP is an endogenous steroid hormone and a biosynthetic intermediate. .
Mevalonate pathway.
Human steroidogenesis, with the major classes of steroid hormones, individual steroids and enzymatic pathways. Changes in molecular structure from a precursor are highlighted in white.
Enzymes, their cellular location, substrates and products in human steroidogenesis. Shown also is the major classes of steroid hormones: progestagens, mineralocorticoids, glucocorticoids, androgens and estrogens. However, they partly overlap, e.g. mineralocorticoids and glucocorticoids. White circles indicate changes in molecular structure compared with precursors. For more information on interpretation of molecular structures, see Wikipedia:structural formula. HSD: Hydroxysteroid dehydrogenase References: Boron WF, Boulpaep EL (2003) Medical Physiology: A Cellular And Molecular Approach, Elsevier/Saunders, pp. page 1,300 ISBN:1-4160-2328-3. For the absence of conversion of corticosterone to cortisol: Steroid hormone biosynthesis Reference pathway (KO).KEGG: Kyoto Encyclopedia of Genes and Genomes. Kyoto University Bioinformatics Center. (1 November 2013). There is no appreciable conversion of corticosterone to cortisol in the adrenal cortex as 21-OH steroids are poor substrates for 17-alpha hydroxylase. Further reading: Hanukoglu I (1992). "Steroidogenic enzymes: structure, function, and role in regulation of steroid hormone biosynthesis". The Journal of Steroid Biochemistry and Molecular Biology43 (8): 779–804. DOI:10.1016/0960-0760(92)90307-5.PMID22217824. Payne AH, Hales DB (2004). "Overview of steroidogenic enzymes in the pathway from cholesterol to active steroid hormones". Endocrine Reviews25 (6): 947–70. DOI:10.1210/er.2003-0030.PMID15583024.See also:Wikiversity:Diagram of the pathways of human steroidogenesis.
HDL and LDL are both protein-lipid complexes. They each carry cholesterol, a type of steroid, to and from the liver respectively.
sterol
Sterol is a chemical compound with formula C17H28O, whose molecule is derived from that of gonane by replacement of a hydrogen atom in position 3 by a hydroxyl group. It is therefore an alcohol of gonane.
The name is also used generically for compounds that are derived from this one by substituting other chemical groups for some of the hydrogen atoms, or modifying the bonds in the ring.
These sterols or steroid alcohols are a subgroup of the steroidsand an important class of organic molecules. They occur naturally in plants, animals, and fungi, and can be also produced by some bacteria (however likely with different functions). The most familiar type of animal sterol is cholesterol, which is vital to cell membrane structure, and functions as a precursor to fat-soluble vitamins and steroid hormones.
While technically alcohols, sterols are classified by biochemists as lipids (fats in the broader sense of the term). (W)
Sterol.
The gonane skeleton, with the IUPAC recommended numbering of the carbon atoms.
sticky and blunt ends
DNA ends refer to the properties of the end of DNA molecules, which may be sticky or blunt based on the enzyme which cuts the DNA. The restriction enzyme belong to a larger class of enzymes called exonucleases and endonucleases. Exonucleases remove nucleotide from ends whereas endonuclease cuts at specific position within the DNA.
The concept is used in molecular biology, especially in cloning or when subcloning inserts DNA into vector DNA. Such ends may be generated by restriction enzymes that cut the DNA – a staggered cut generates two sticky ends, while a straight cut generates blunt ends. (W)
stop codon
In molecular biology (specifically protein biosynthesis), a stop codon (or termination codon) is a codon (nucleotide triplet within messenger RNA) that signals the termination of the translation process of the current protein. Most codons in messenger RNA correspond to the addition of an amino acid to a growing polypeptide chain, which may ultimately become a protein; stop codons signal the termination of this process by binding release factors, which cause the ribosomal subunits to disassociate, releasing the amino acid chain.
While start codons need nearby sequences or initiation factors to start translation, a stop codon alone is sufficient to initiate termination.
Stop codon (red dot) of the human mitochondrial DNA MT-ATP8 gene, and start codon (blue circle) of the MT-ATP6 gene. For each nucleotide triplet (square brackets), the corresponding amino acid is given (one-letter code), either in the +1 reading frame for MT-ATP8 (in red) or in the +3 frame for MT-ATP6 (in blue). In this genomic region, the two genes overlap.
The human genes MT-ATP8 and MT-ATP6 located in the mitochondrial DNA and coding for the ATP synthase F0 subunits 8 and 6 overlap on 46 nucleotides. The DNA sequence of this region of the human mitochondrial genome is given in black (positions 8,525 to 8,580 in the sequence accession NC_012920). There are three possible reading frames in the 5' -> 3' forward direction, starting on the first (+1), second (+2) and third position (+3). For each nucleotide triplet (square brackets), the corresponding amino acid is given (one-letter code), either in the +1 frame for MT-ATP8 (in red) or in the +3 frame for MT-ATP6 (in blue). The MT-ATP8 genes terminates with the TAG stop codon (red dot) in the +1 frame. The MT-ATP6 gene starts with the ATG codon (blue circle for the M amino acid) in the +3 frame. Forteen sense codons do overlap for the two genes. As both genes use different ORF, the two protein sequences are different in the overlap region.
structural formula
The structural formula of a chemical compound is a graphic representation of the molecular structure (determined by structural chemistry methods), showing how the atoms are possibly arranged in the real three-dimensional space. The chemical bonding within the molecule is also shown, either explicitly or implicitly. Unlike chemical formulas, which have a limited number of symbols and are capable of only limited descriptive power, structural formulas provide a more complete geometric representation of the molecular structure. For example, many chemical compounds exist in different isomeric forms, which have different enantiomeric structures but the same chemical formula.(W)
In chemistry, a substrate is typically the chemical species being observed in a chemical reaction, which reacts with a reagent to generate a product. It can also refer to a surface on which other chemical reactions are performed, or play a supporting role in a variety of spectroscopic and microscopic techniques. In synthetic and organic chemistry, the substrate is the chemical of interest that is being modified. In biochemistry, an enzyme substrate is the material upon which an enzyme acts. When referring to Le Chatelier's principle, the substrate is the reagent whose concentration is changed. The term substrate is highly context-dependent.
Spontaneous reaction
S → P
Where S is substrate and P is product.
Catalysed reaction
S+ C→ P + C
Where S is substrate, P is product and C is catalyst.
sulfate
The sulfate or sulphate (see spelling differences) ion is a polyatomicanion with the empirical formula SO42-. Sulfate is the spelling recommended by IUPAC, but sulphate is used in British English. Salts, acid derivatives, and peroxides of sulfate are widely used in industry. Sulfates occur widely in everyday life. Sulfates are salts of sulfuric acid and many are prepared from that acid.(W)
The structure and bonding of the sulfate ion. The distance between the sulfur atom and an oxygen atom is 149 picometers.
Past and ongoing research continues to elucidate the many biological functions of sulfatide and their many implications as well as the pathology that has been associated with sulfatide. Most research utilizes mice models, but heterologous expression systems are utilized as well, including, but not limited to, Madin-Darby canine kidney cells and COS-7 Cells.
A supramolecular assembly or "supermolecule" is a well defined complex of molecules held together by noncovalent bonds. While a supramolecular assembly can be simply composed of two molecules (e.g., a DNAdouble helix or an inclusion compound), it is more often used to denote larger complexes of molecules that form sphere-, rod-, or sheet-like species. Micelles,liposomes and biological membranes are examples of supramolecular assemblies. The dimensions of supramolecular assemblies can range from nanometers to micrometers. Thus they allow access to nanoscale objects using a bottom-up approach in far fewer steps than a single molecule of similar dimensions.
The process by which a supramolecular assembly forms is called molecular self-assembly. Some try to distinguish self-assembly as the process by which individual molecules form the defined aggregate. Self-organization, then, is the process by which those aggregates create higher-order structures. This can become useful when talking about liquid crystals and block copolymers.(W)
In this example two pyrene butyric acids are bound within a hexameric nanocapsule composed of six C-hexylpyrogallol arenes held together by hydrogen bonds. The side chains of the pyrene butyric acids are omitted.

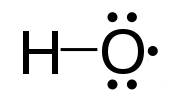


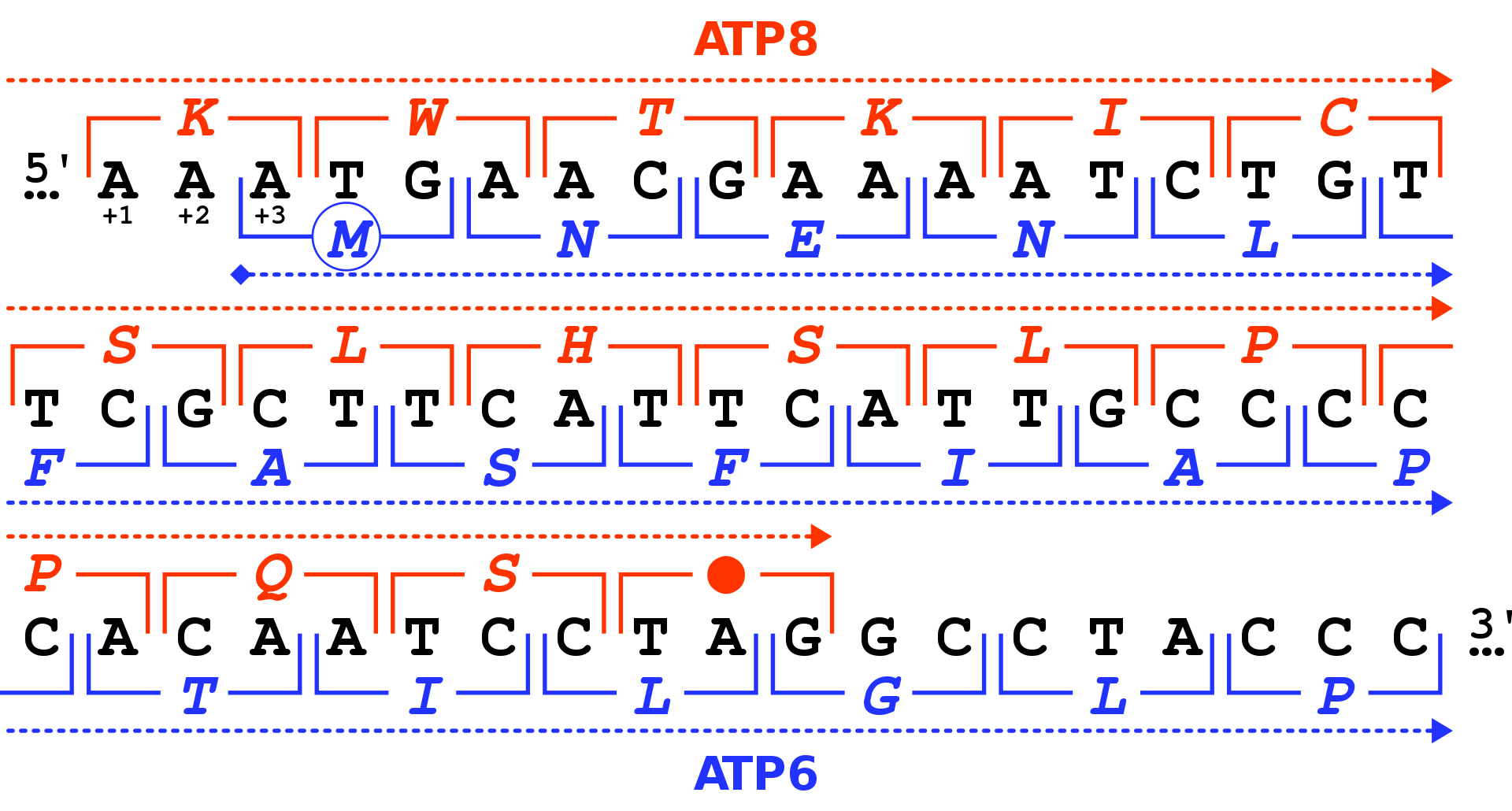
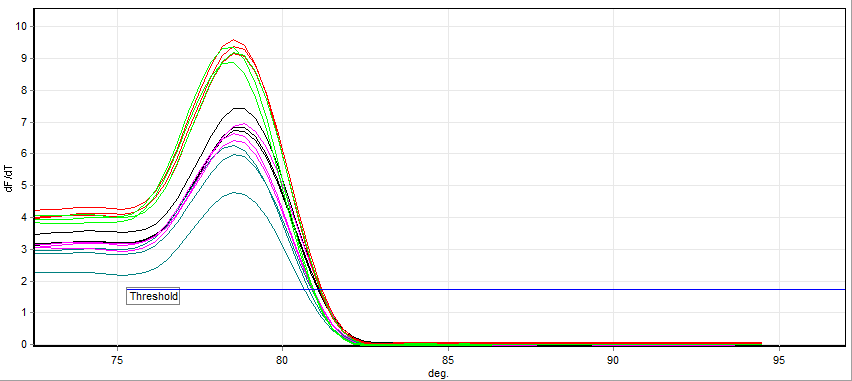
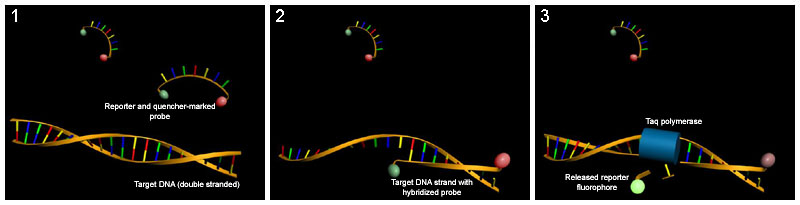
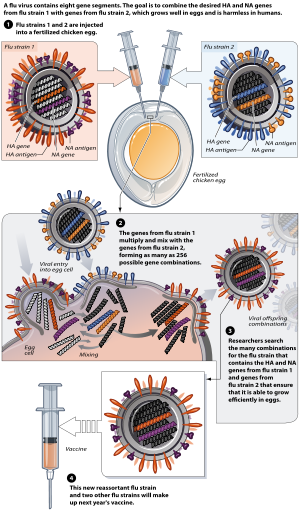
.png)
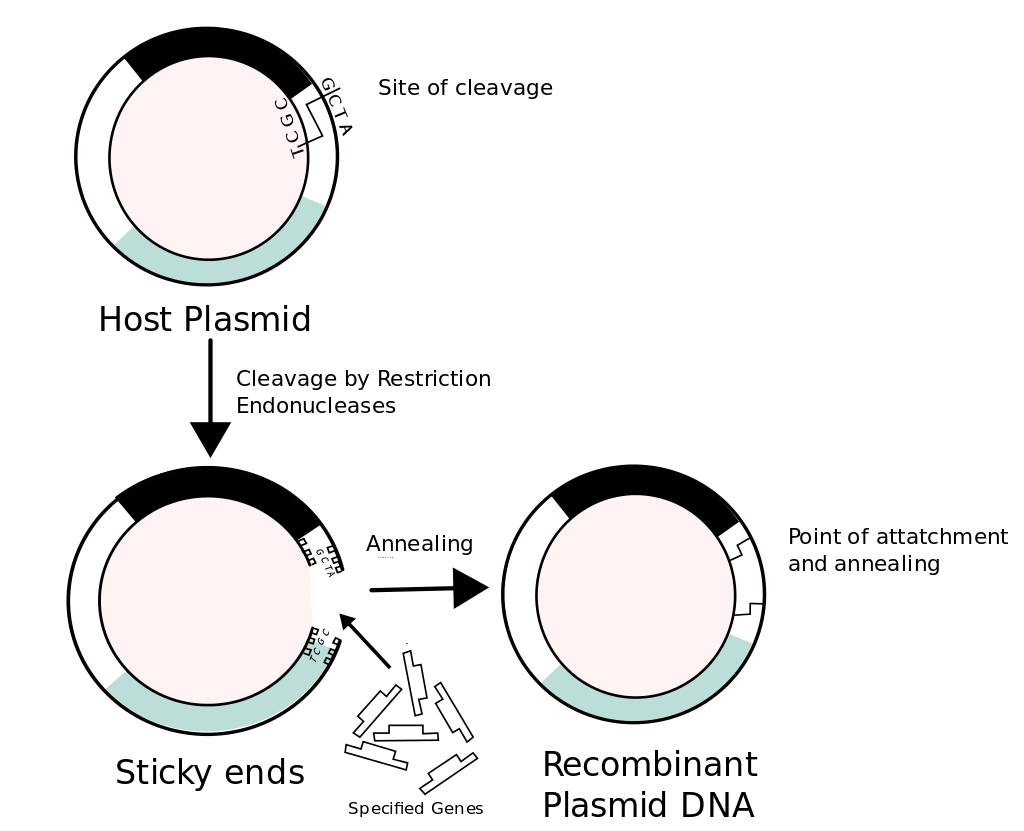
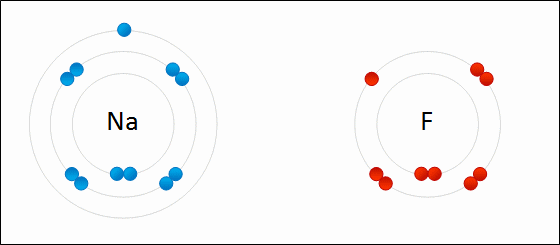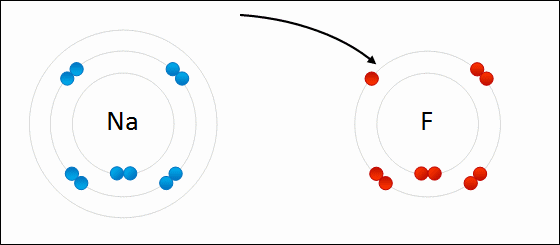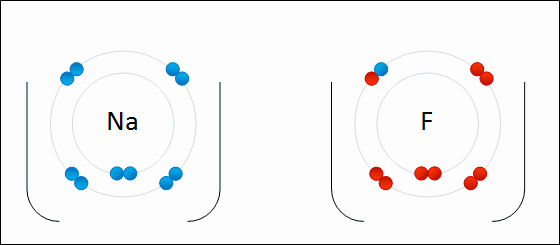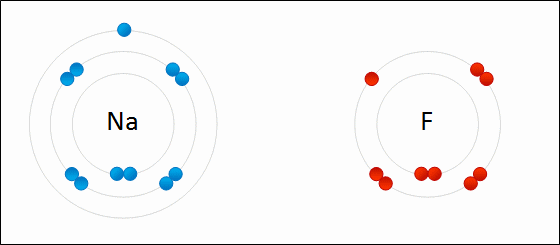
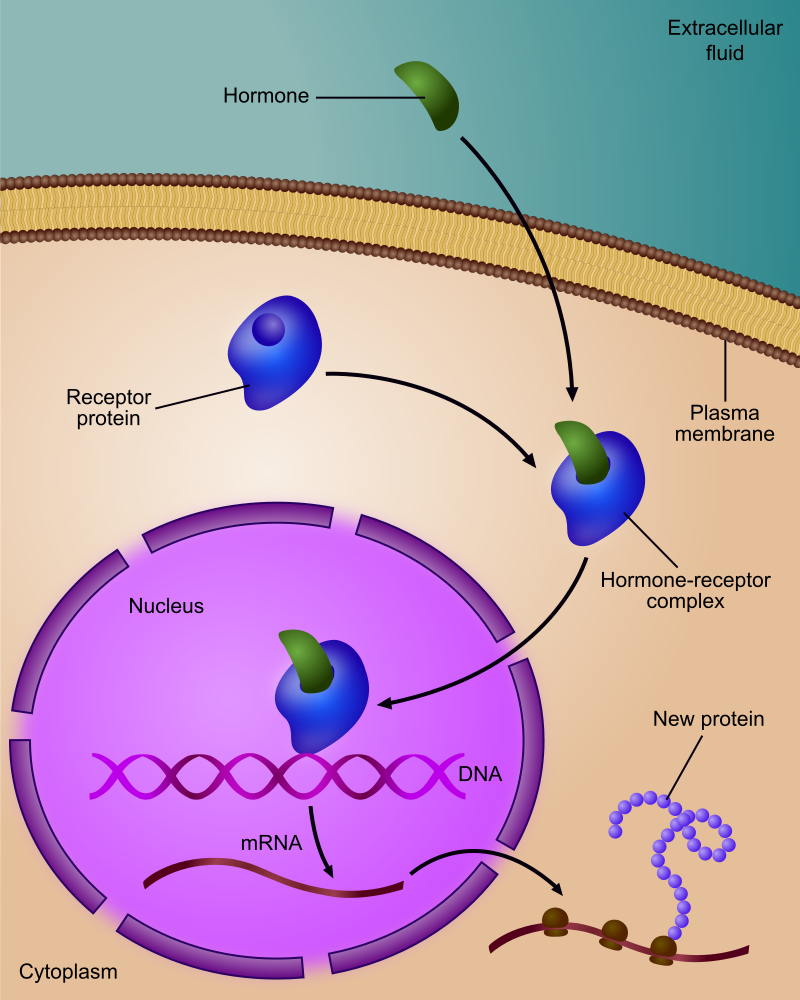
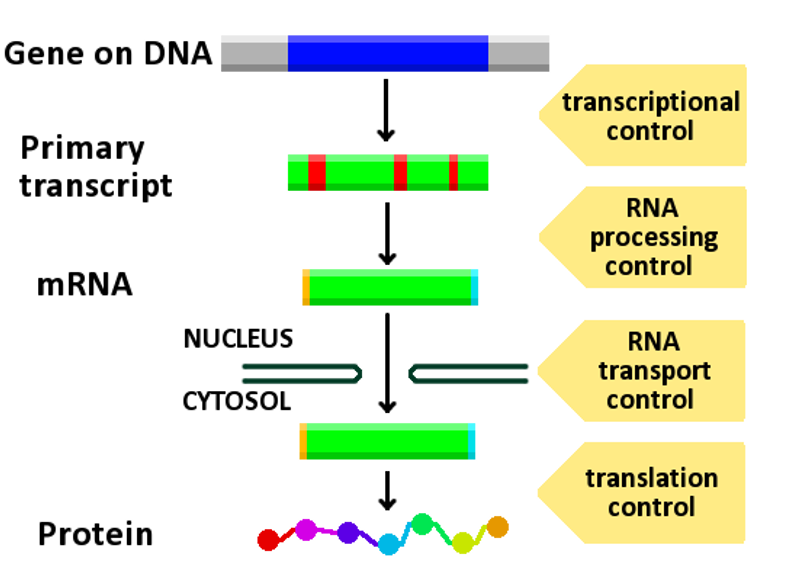
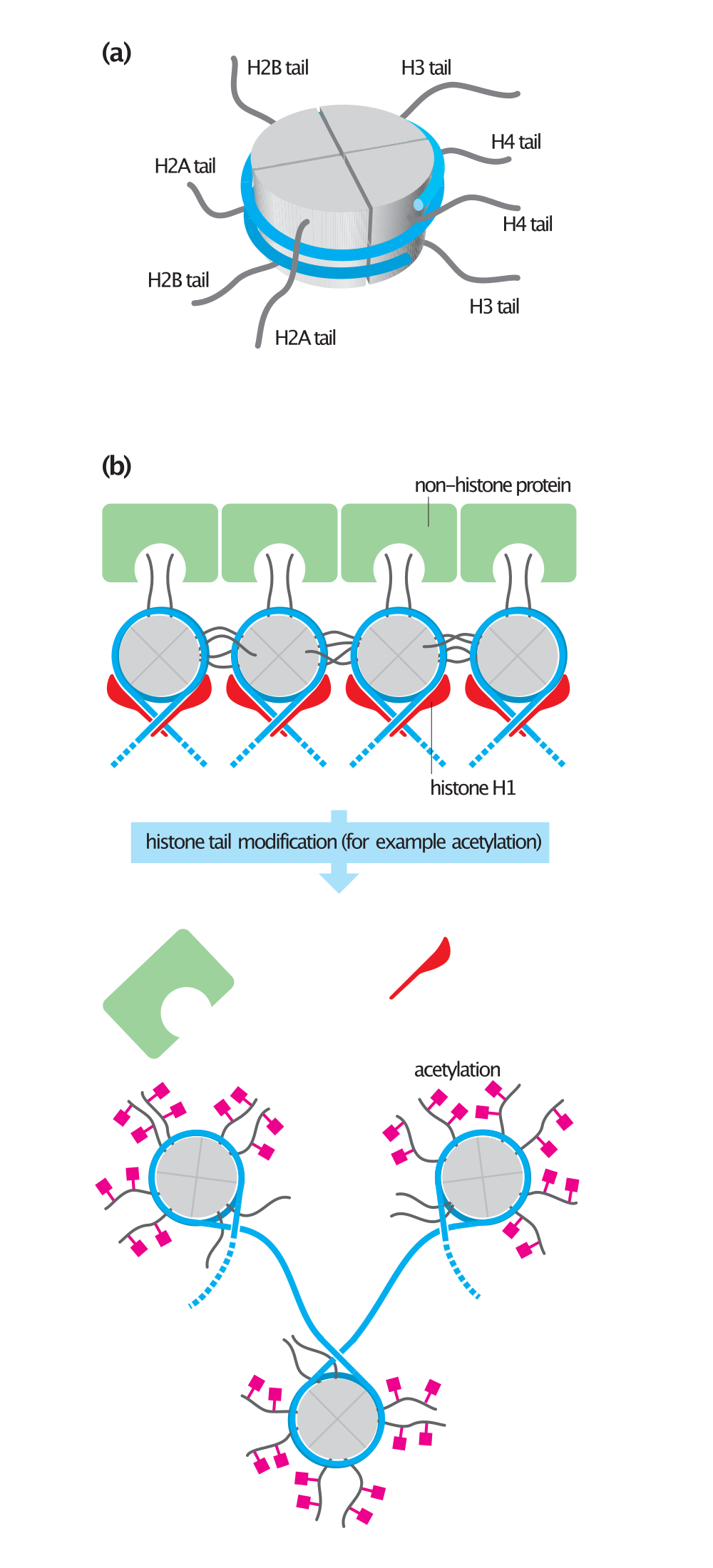
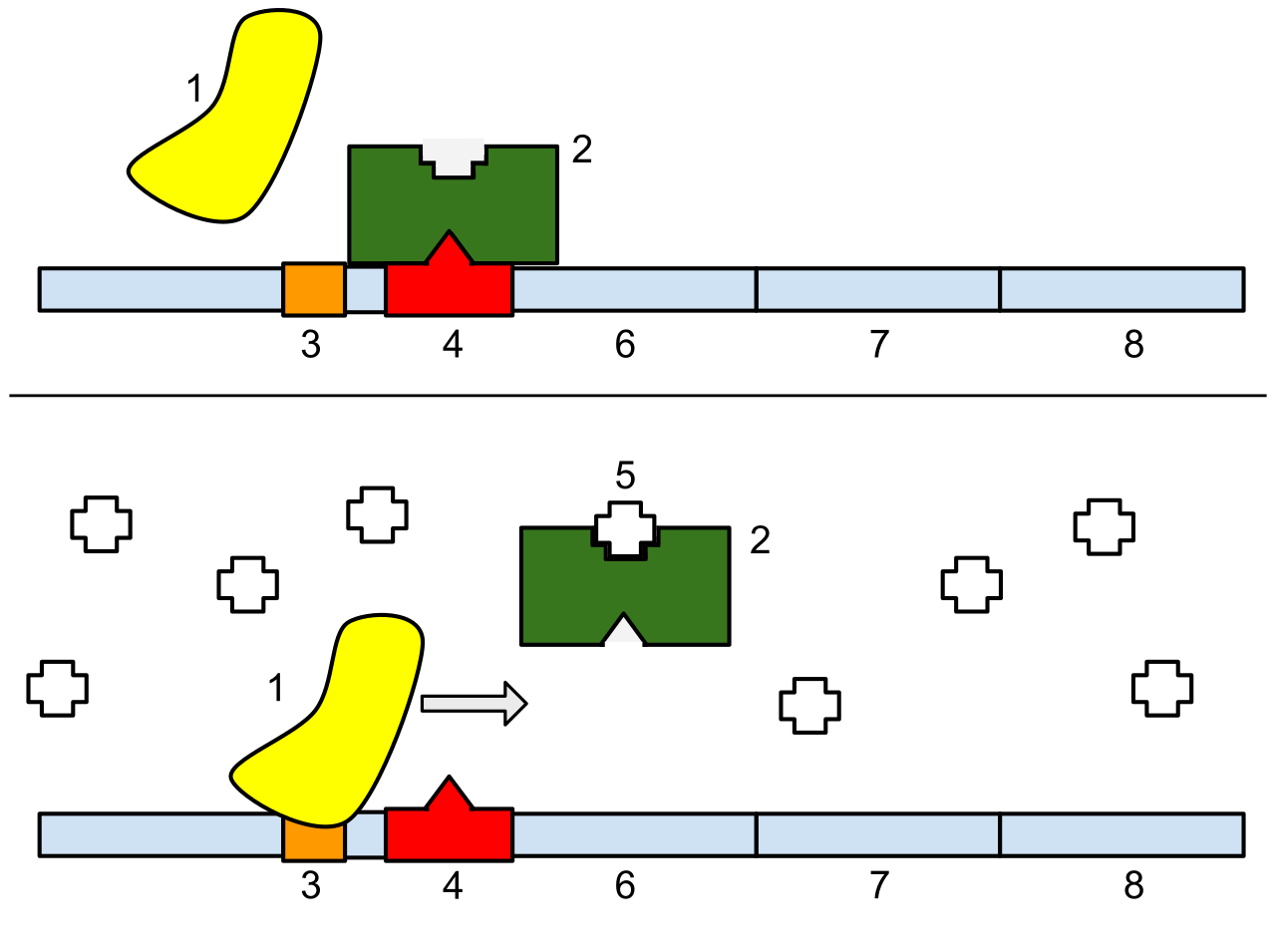
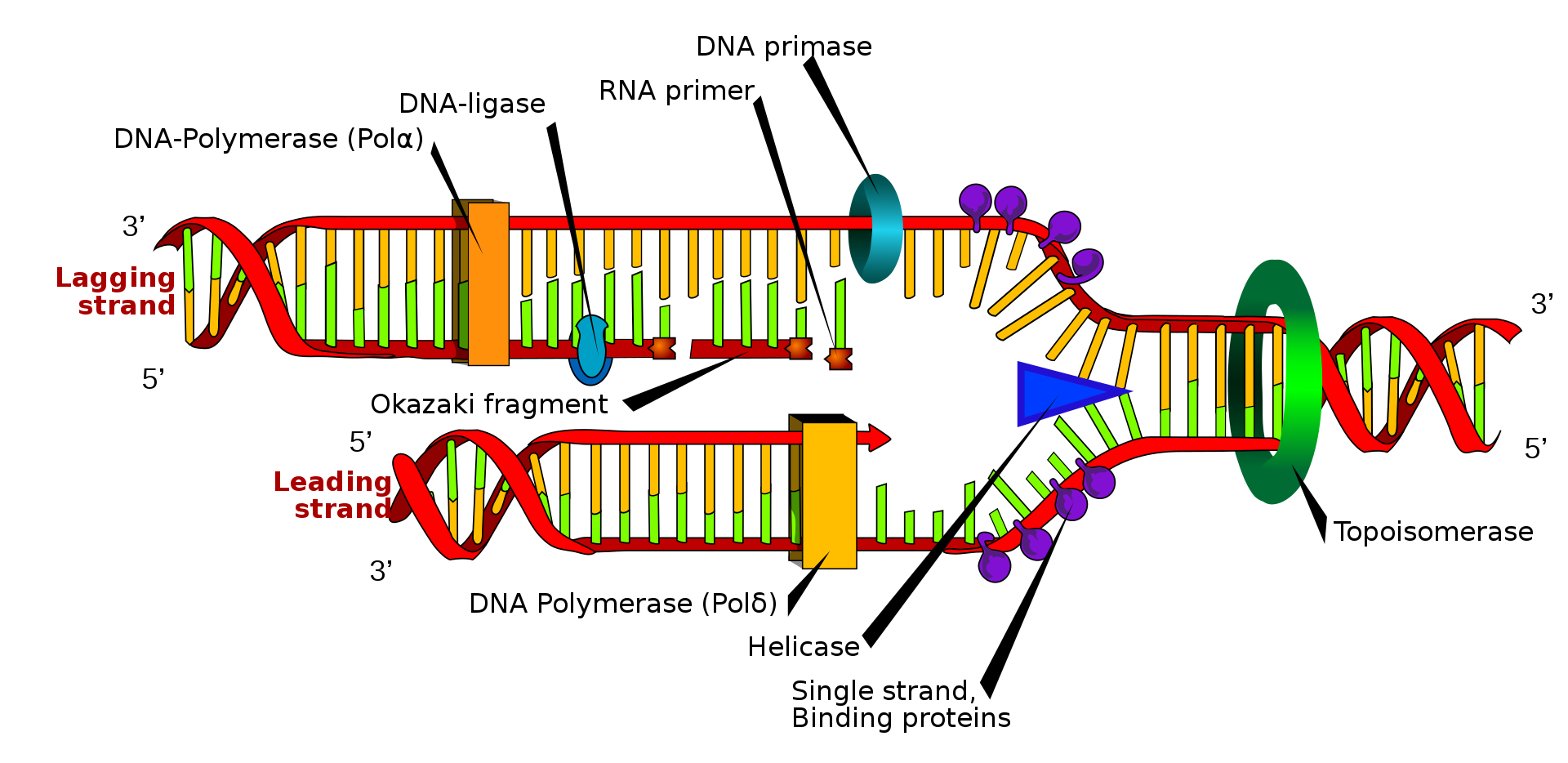
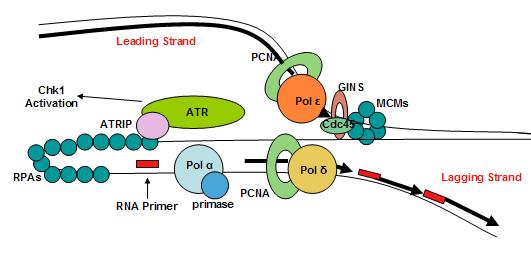
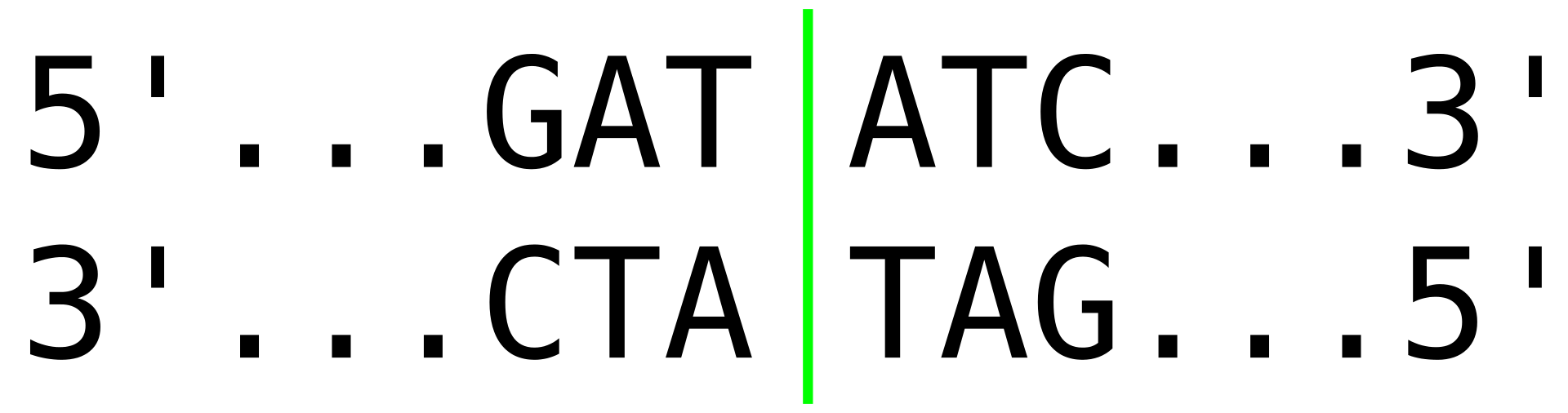
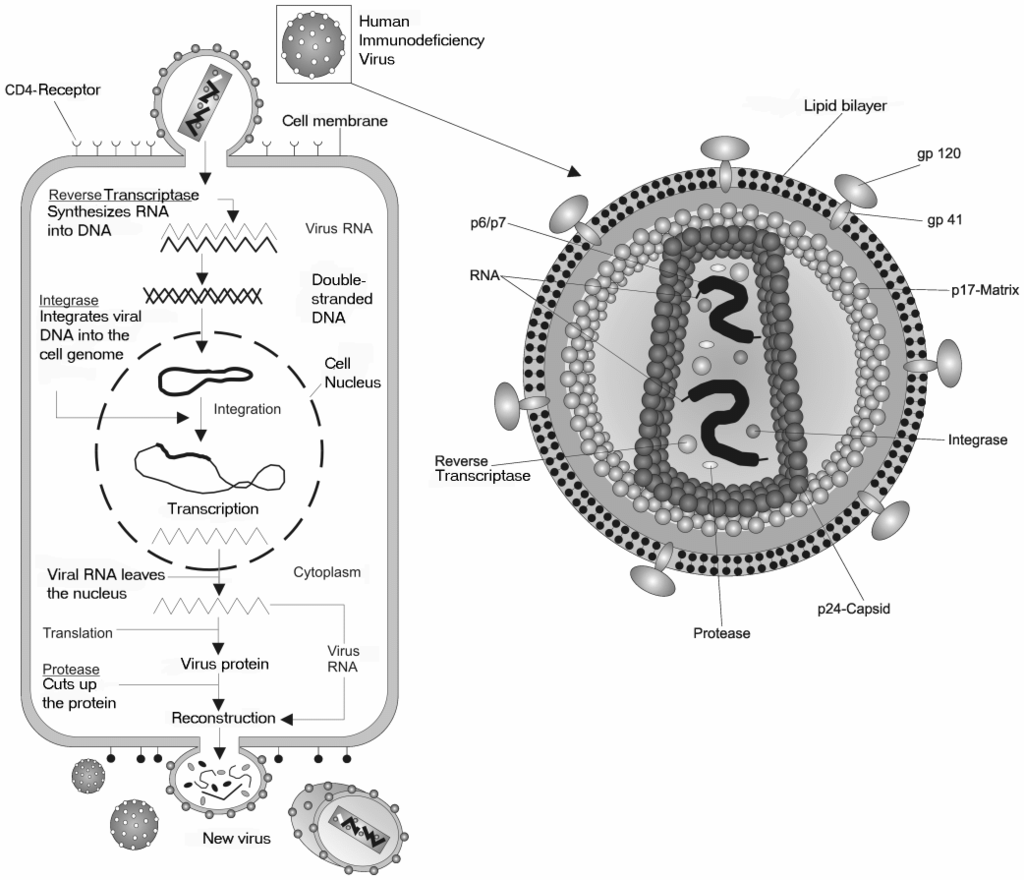
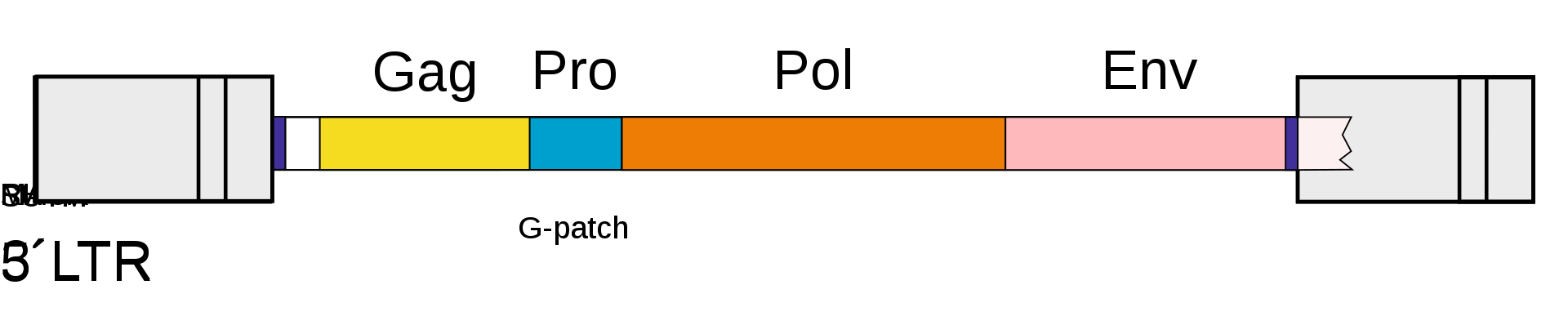
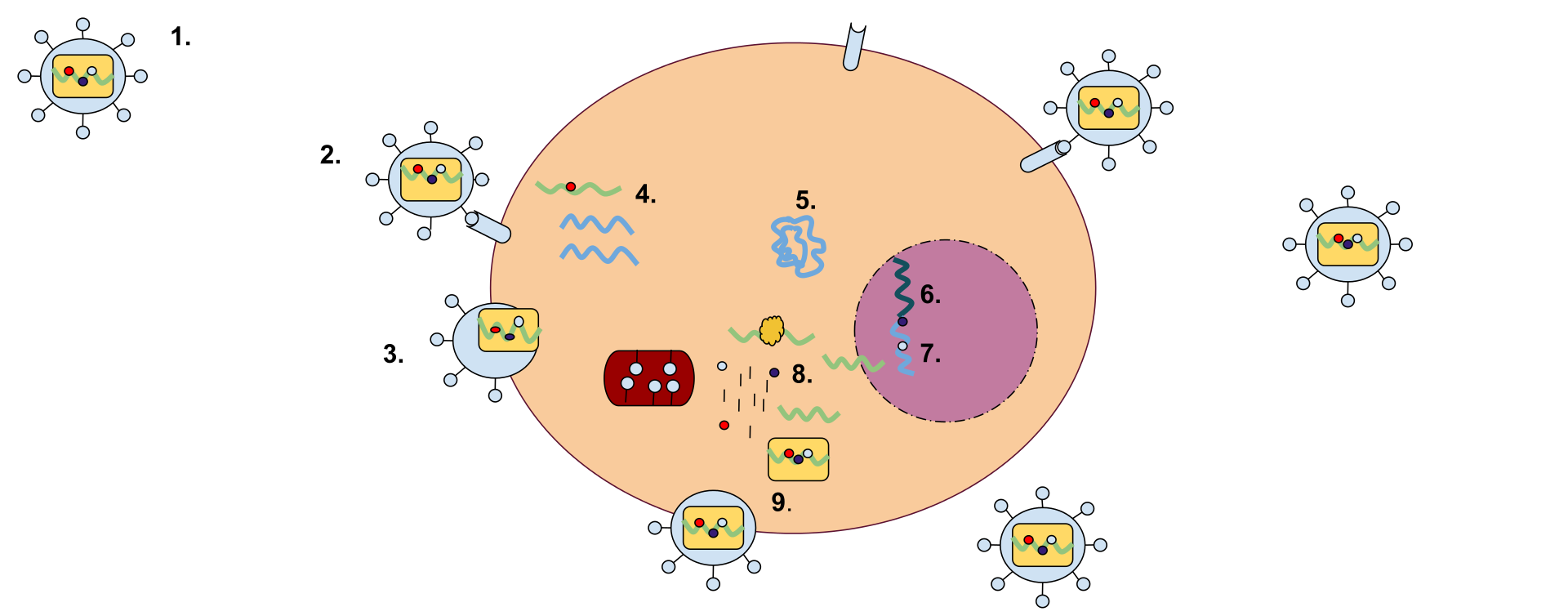

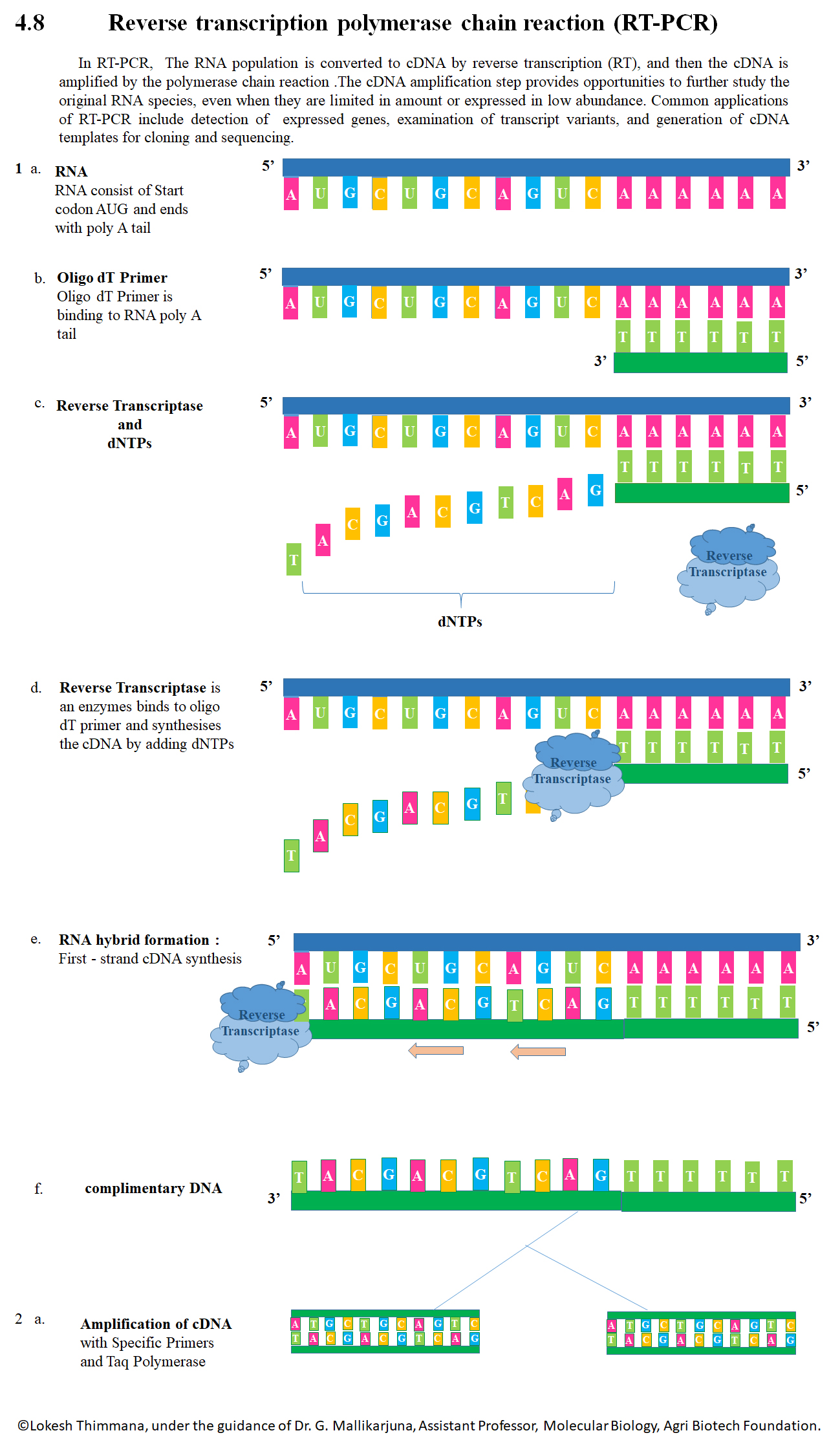
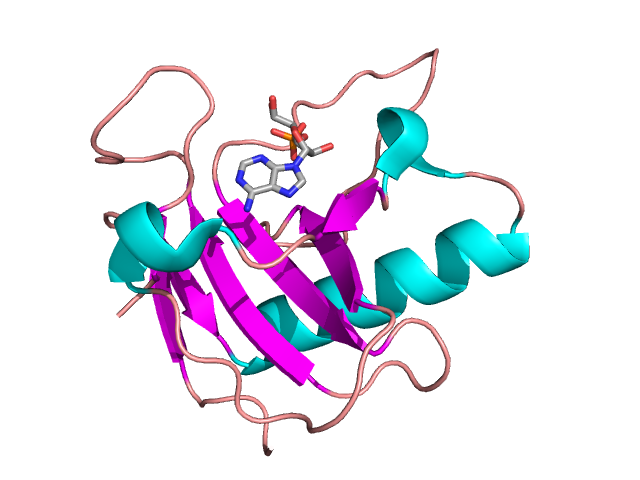
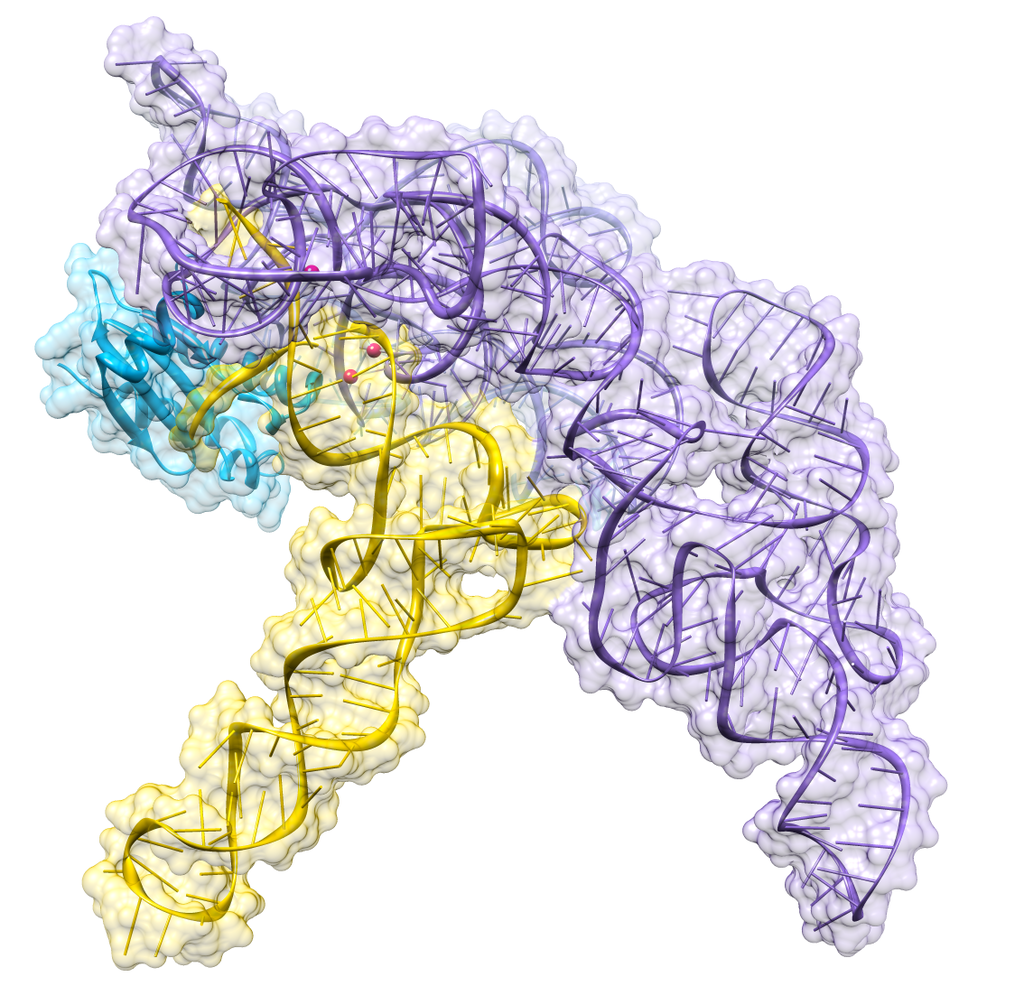
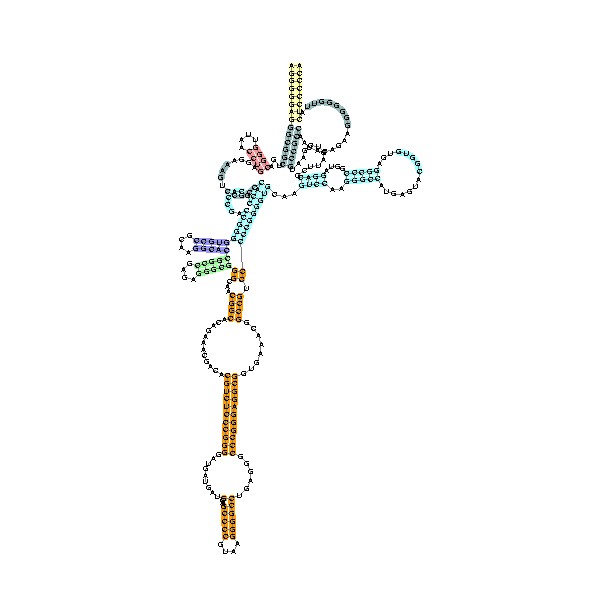
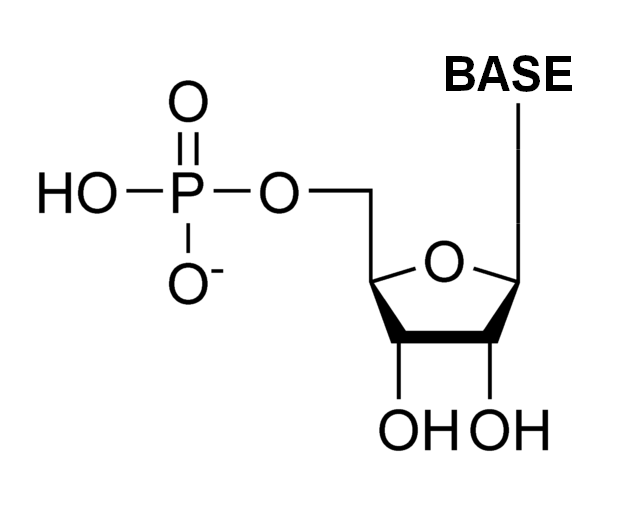
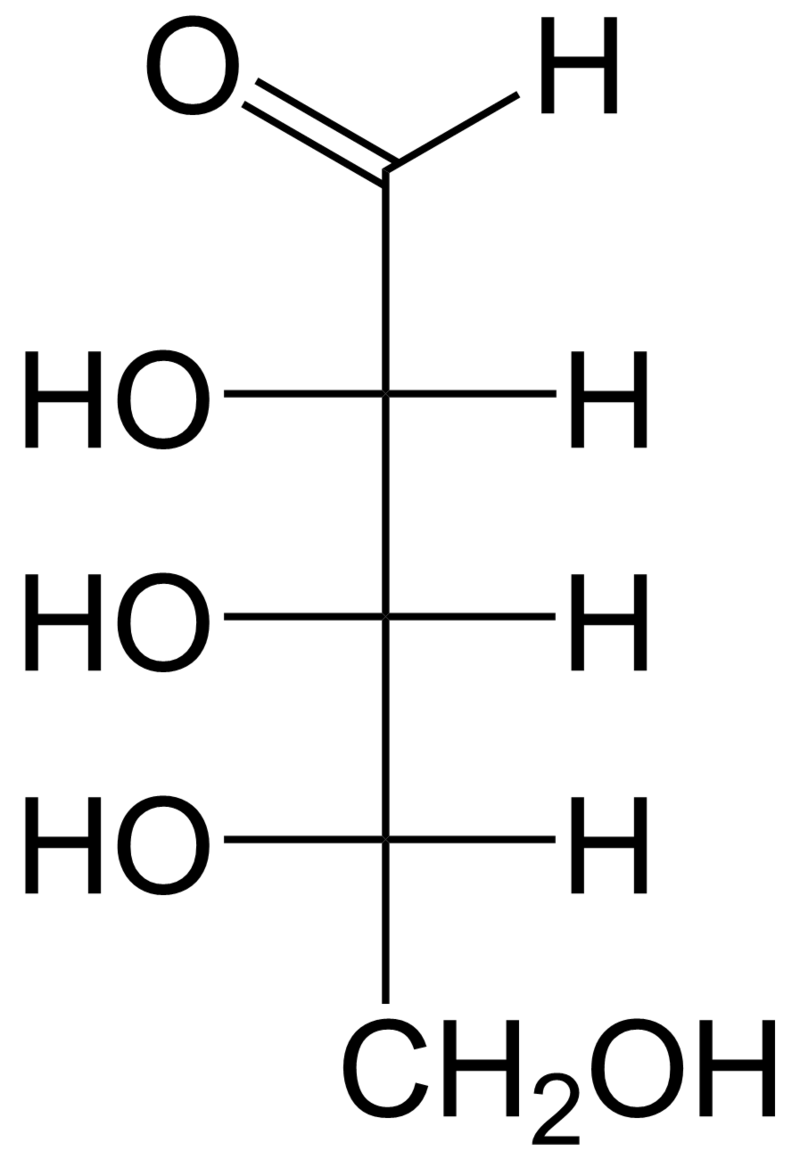
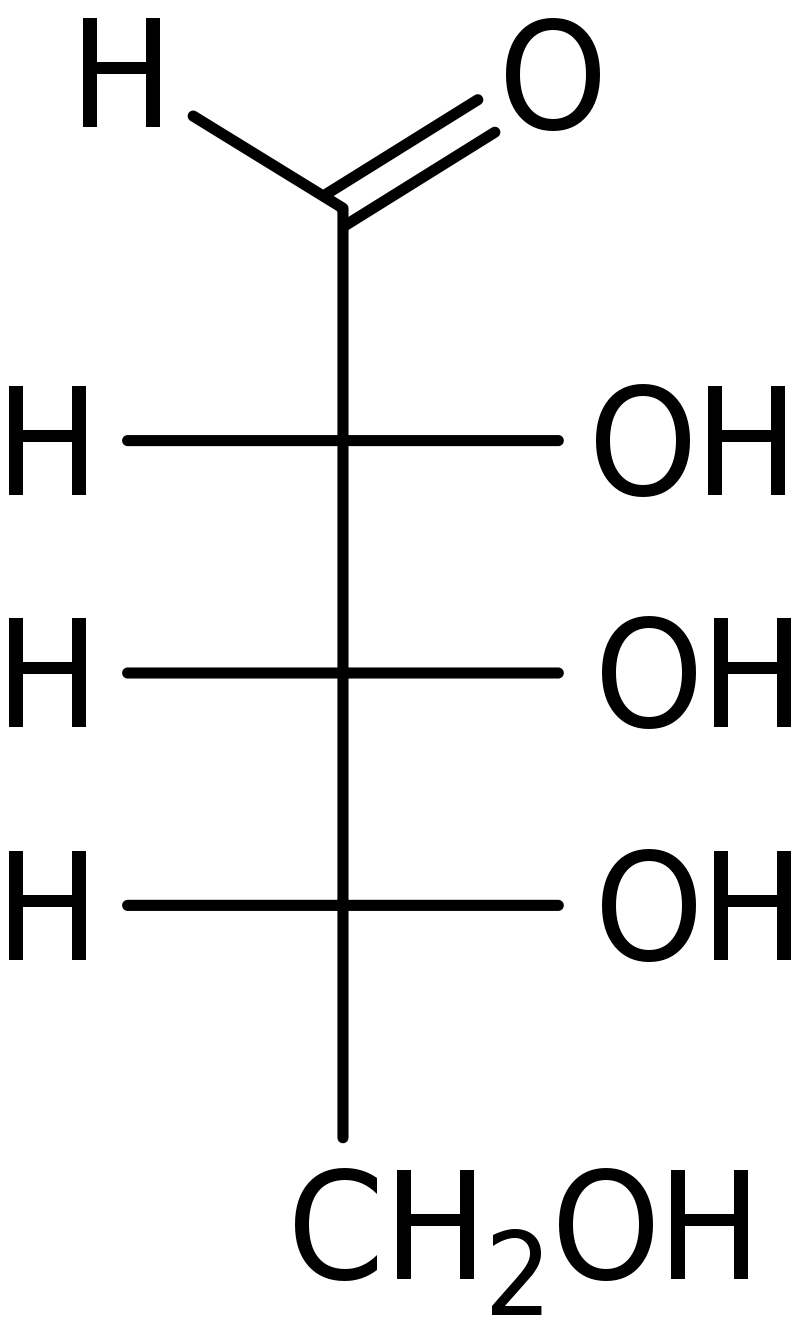
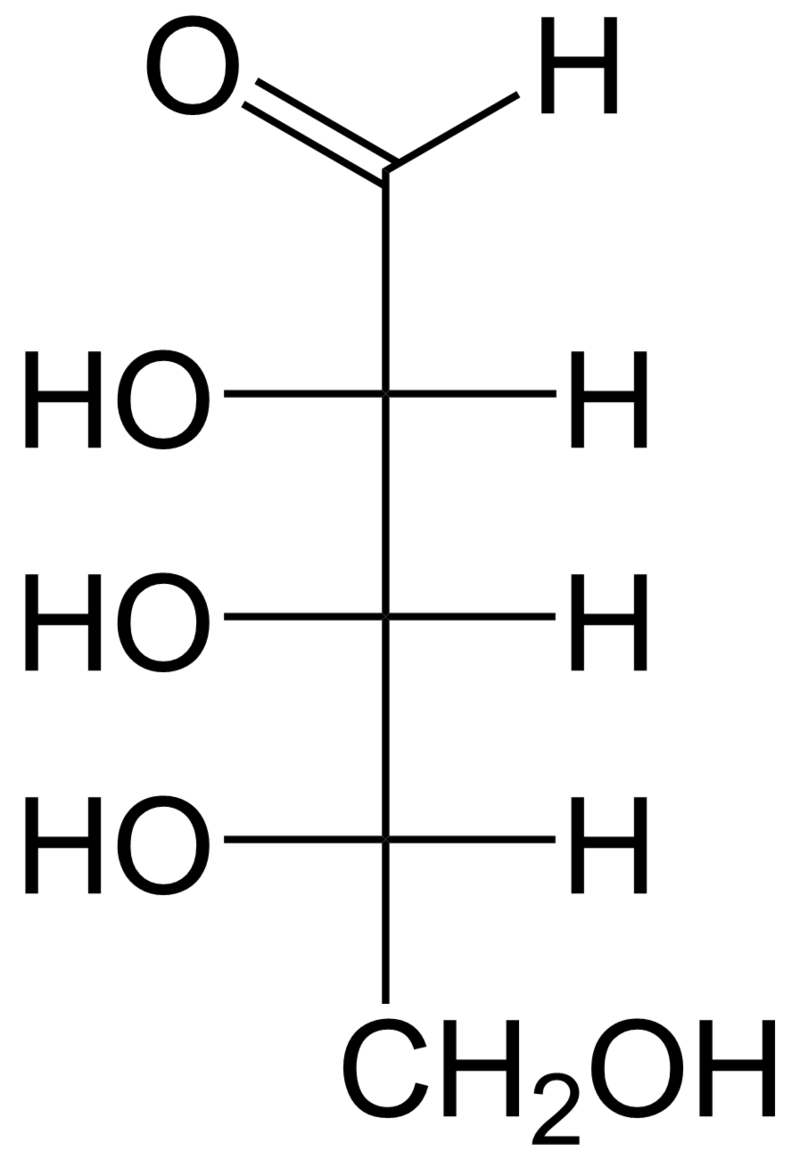
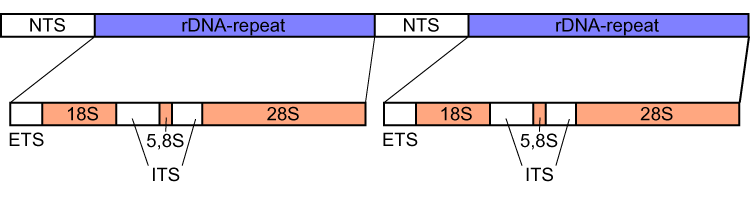
.png)
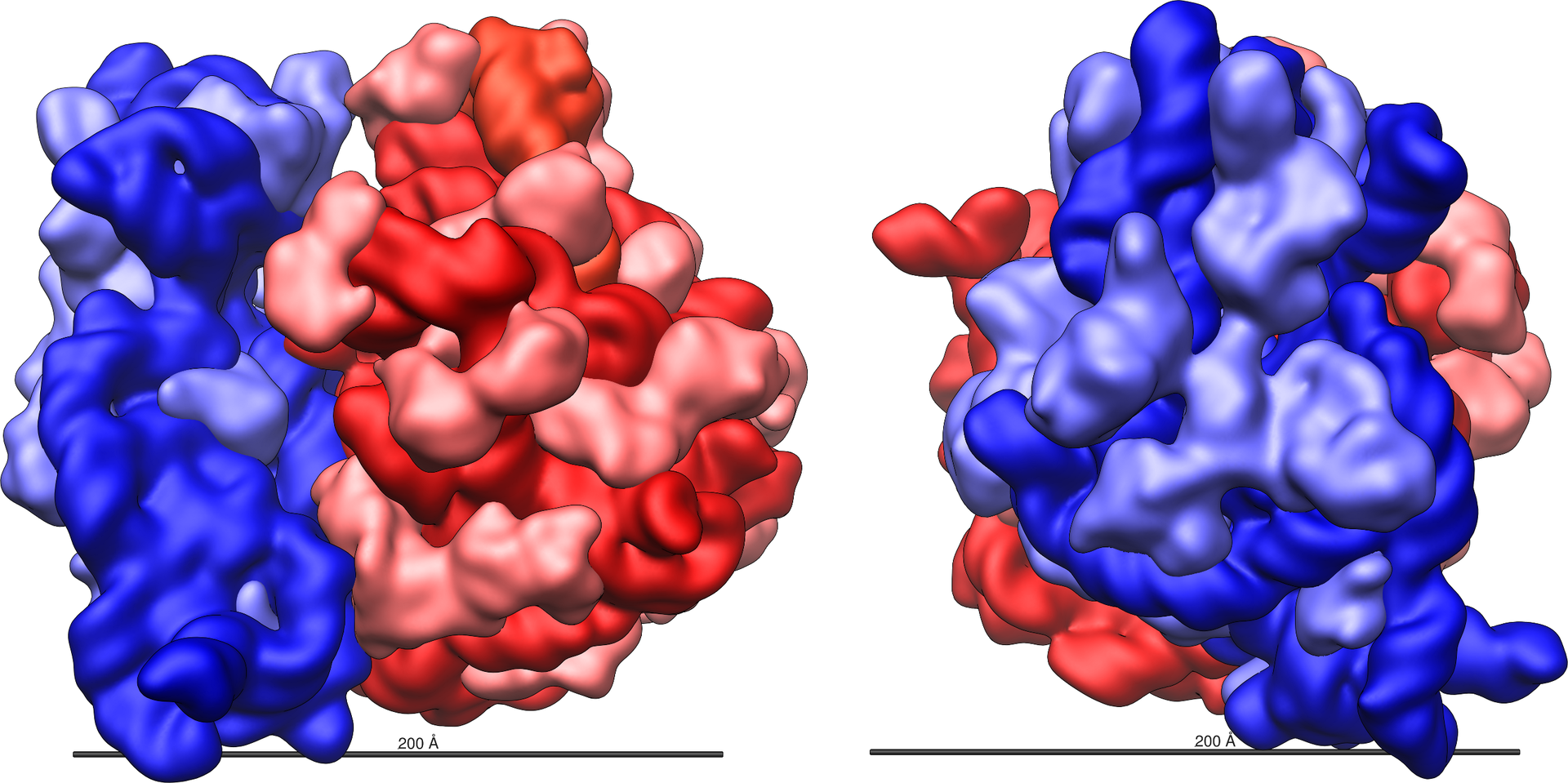
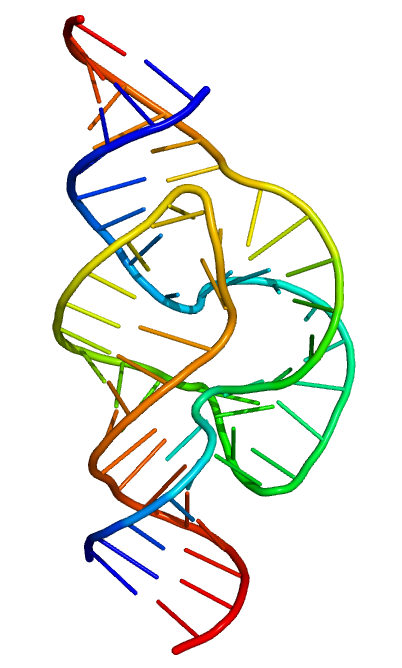
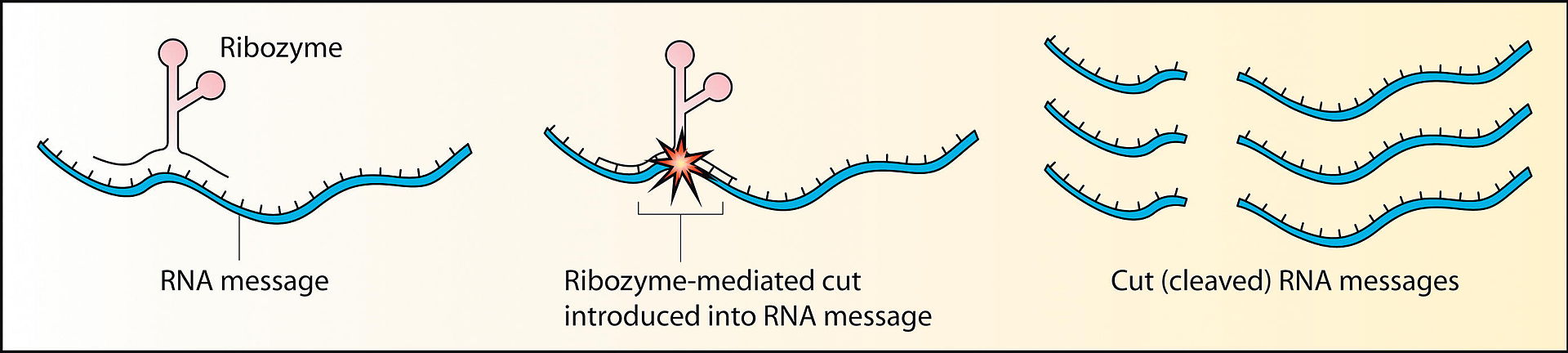
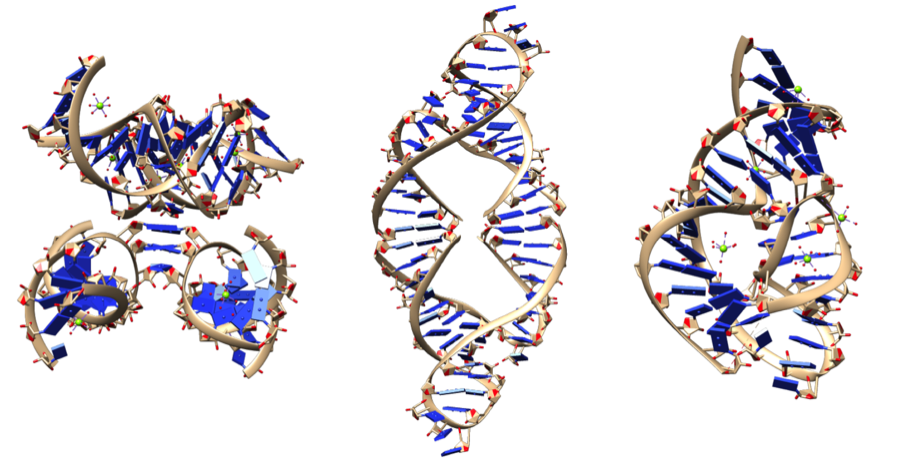
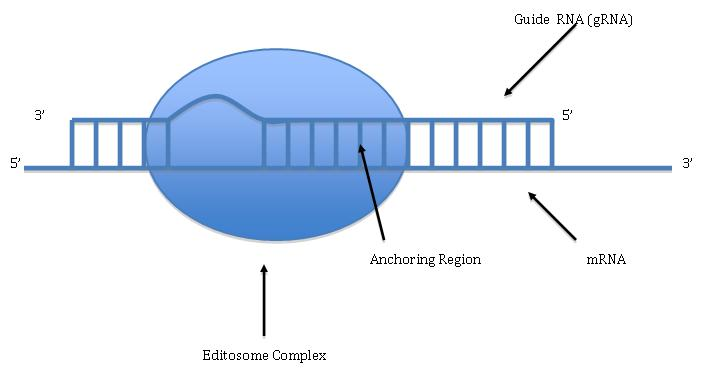
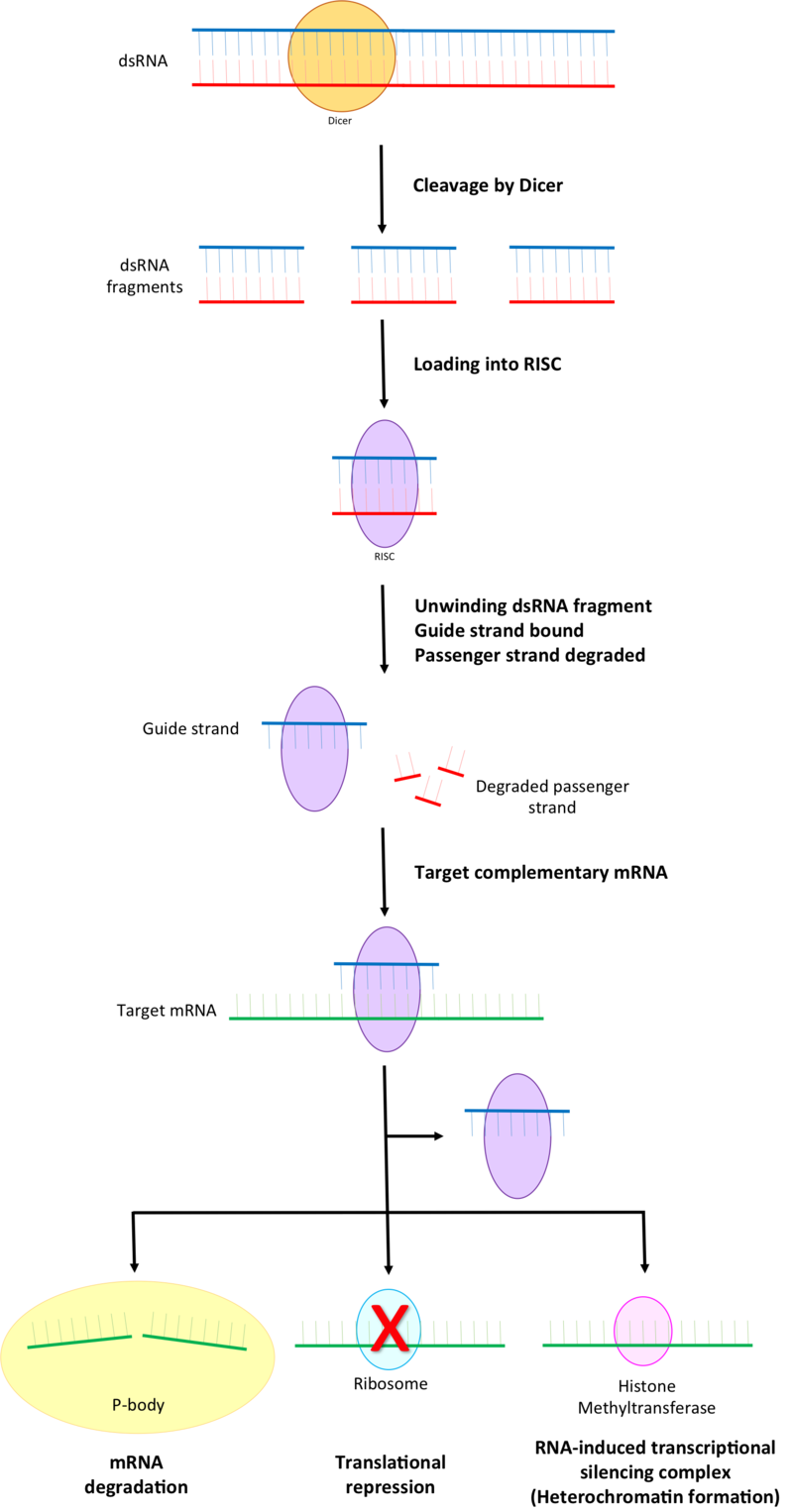
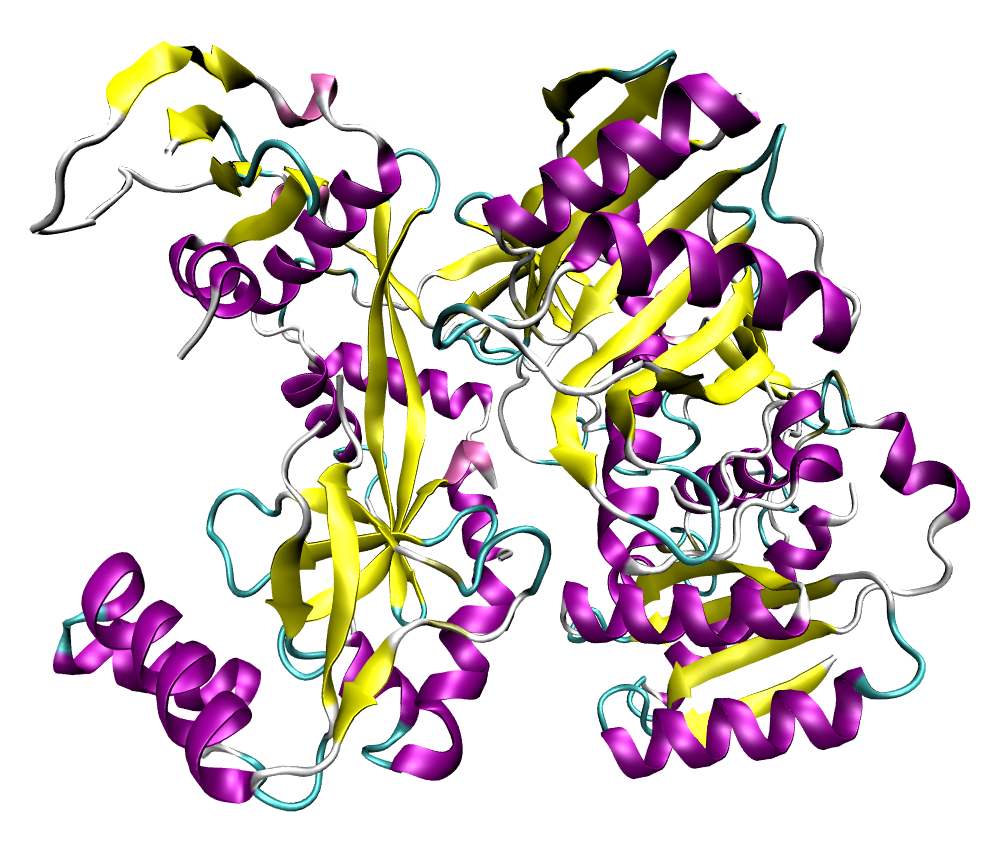
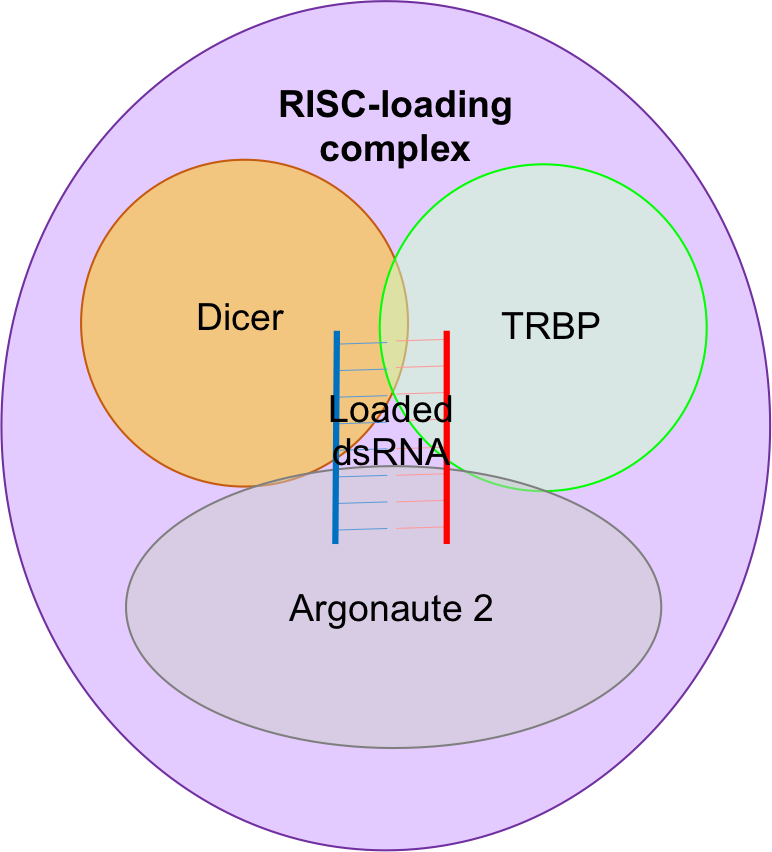
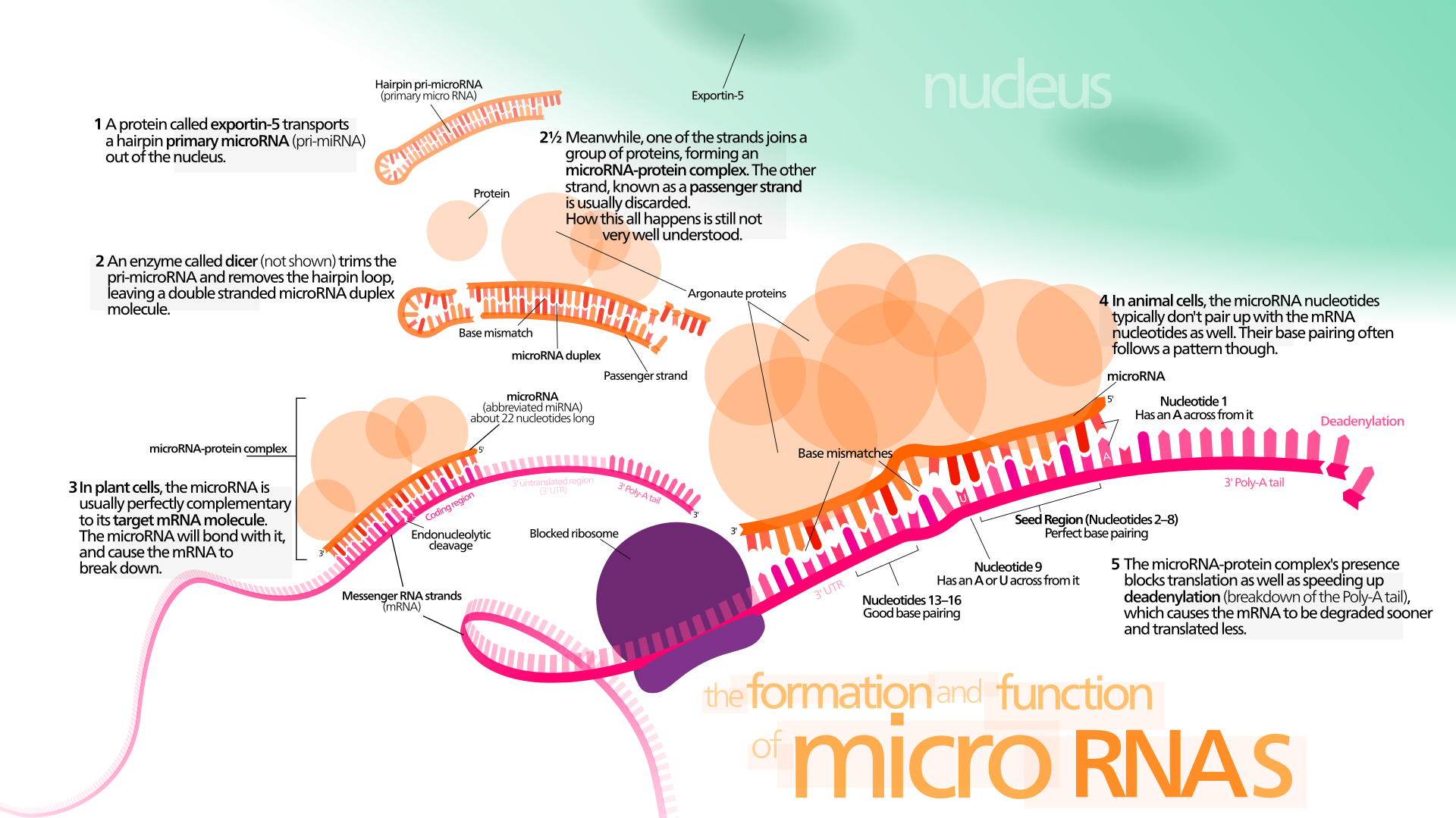
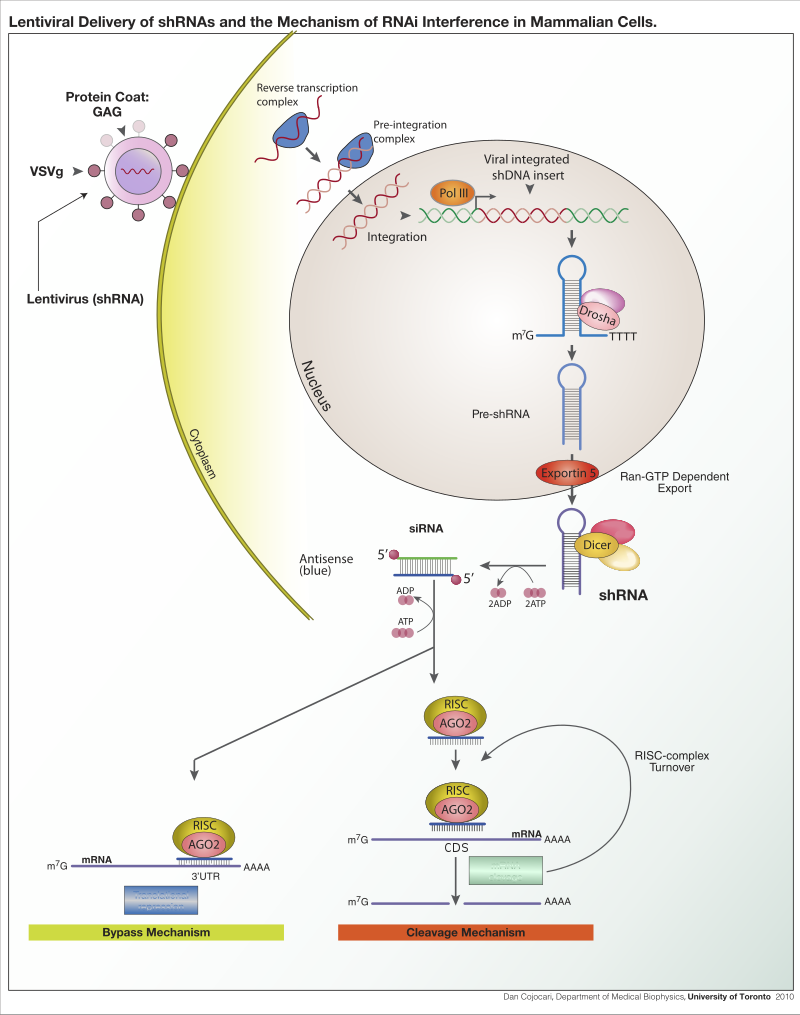
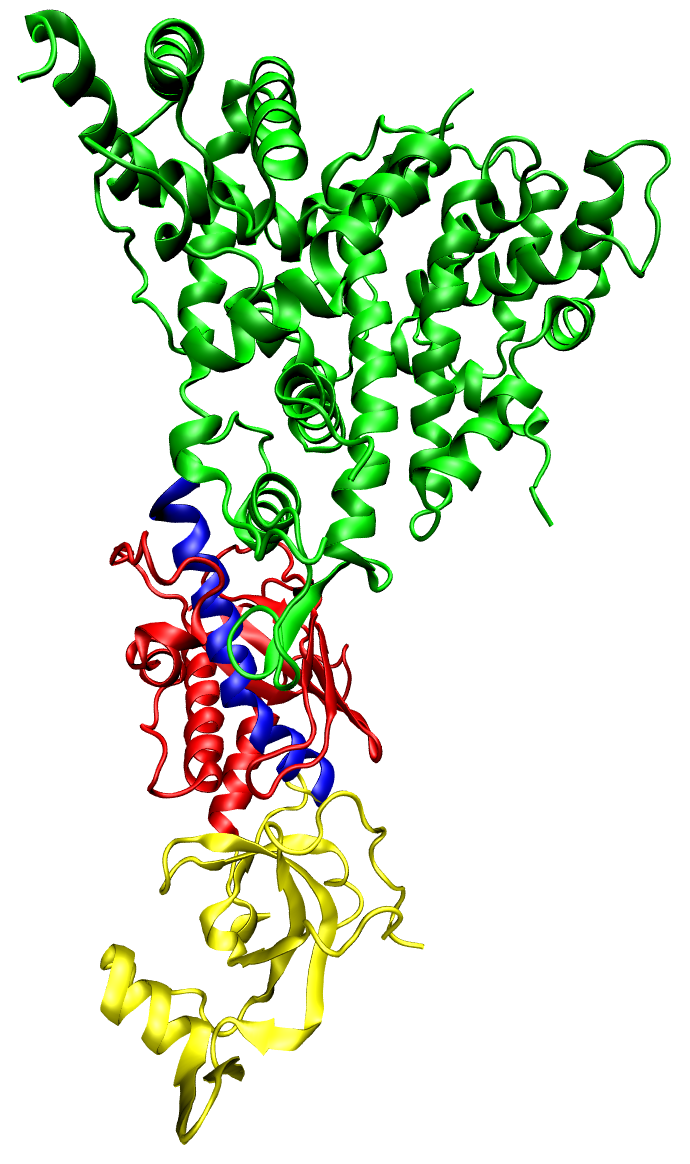
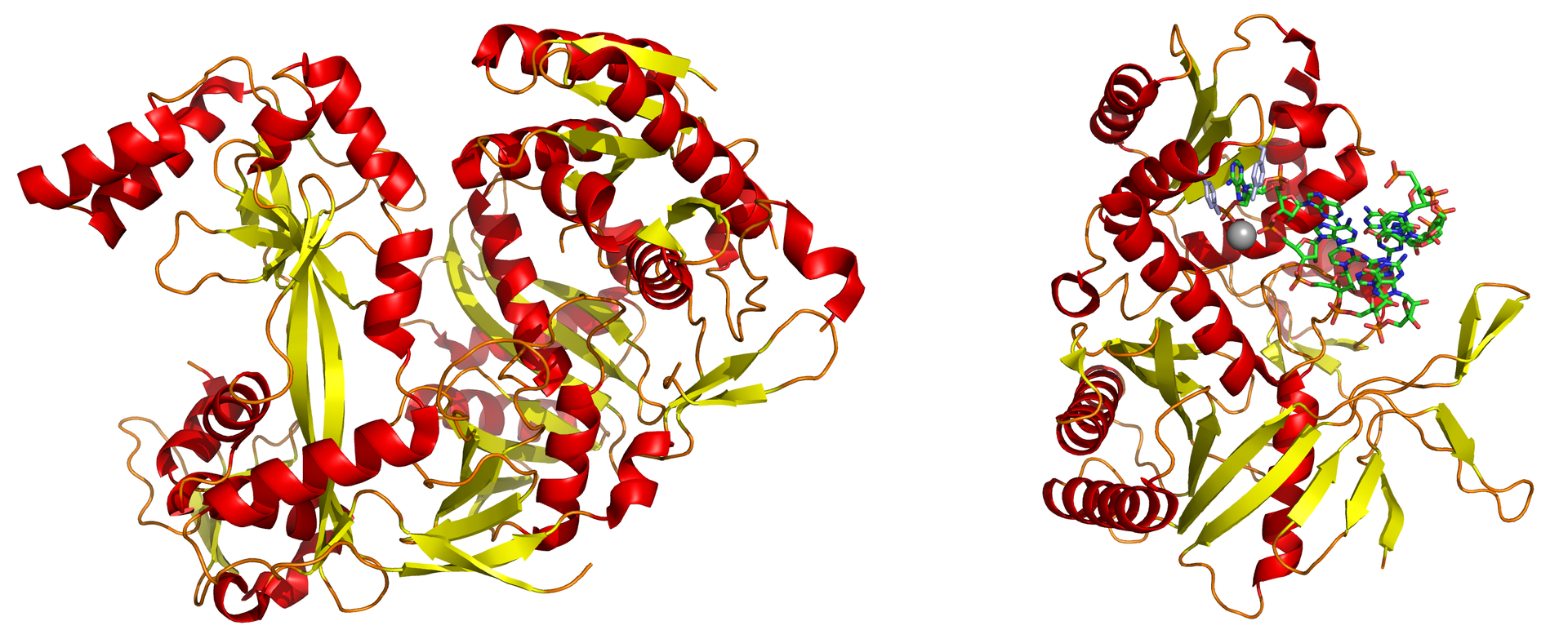
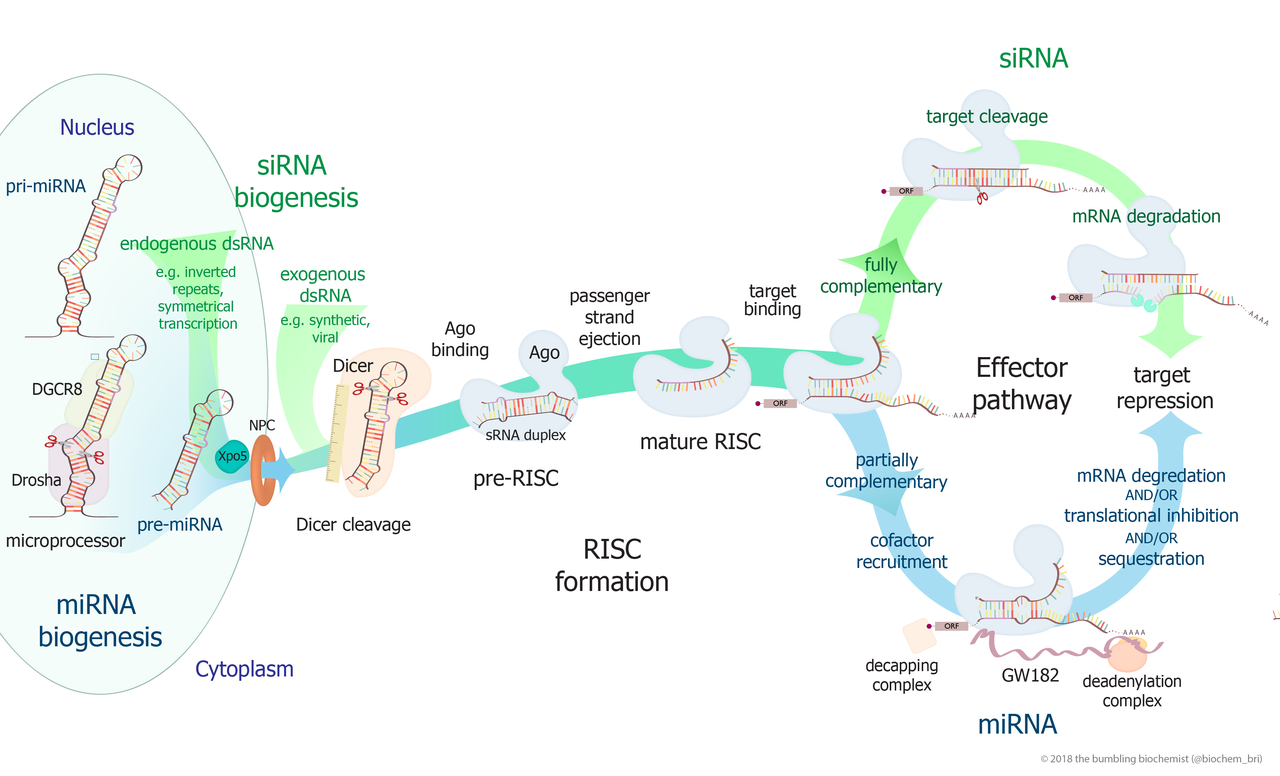
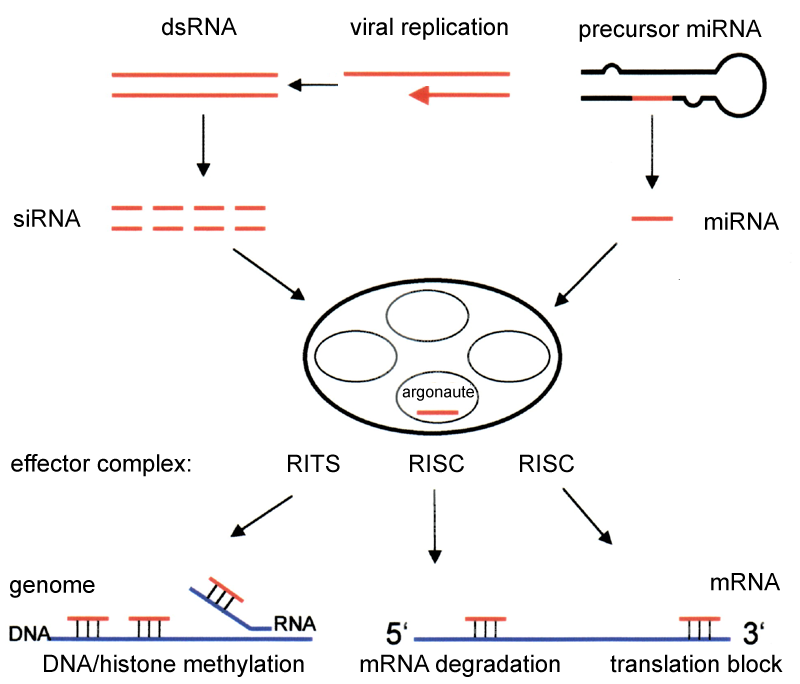
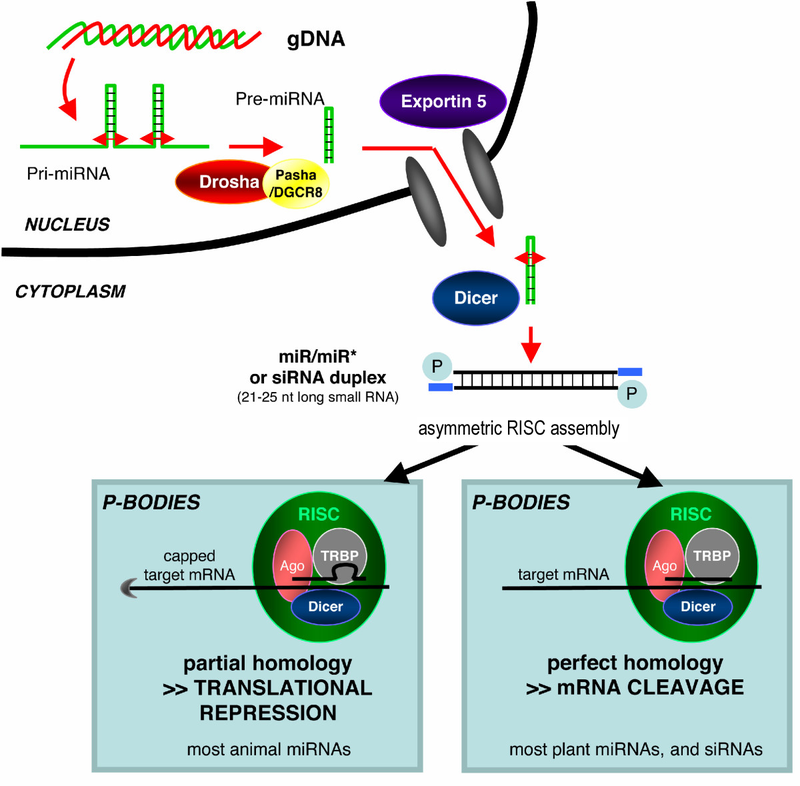


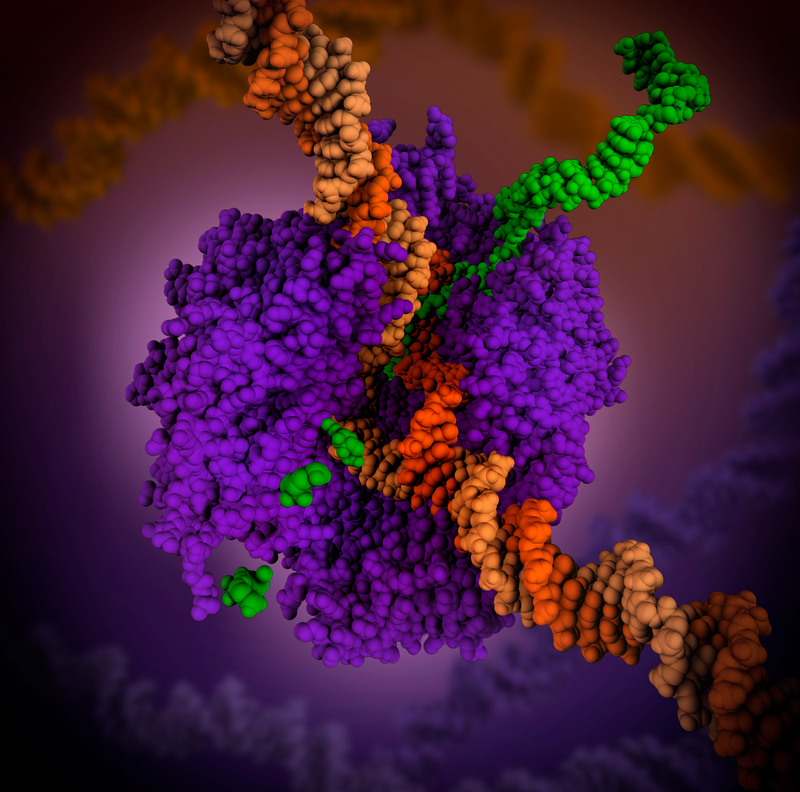
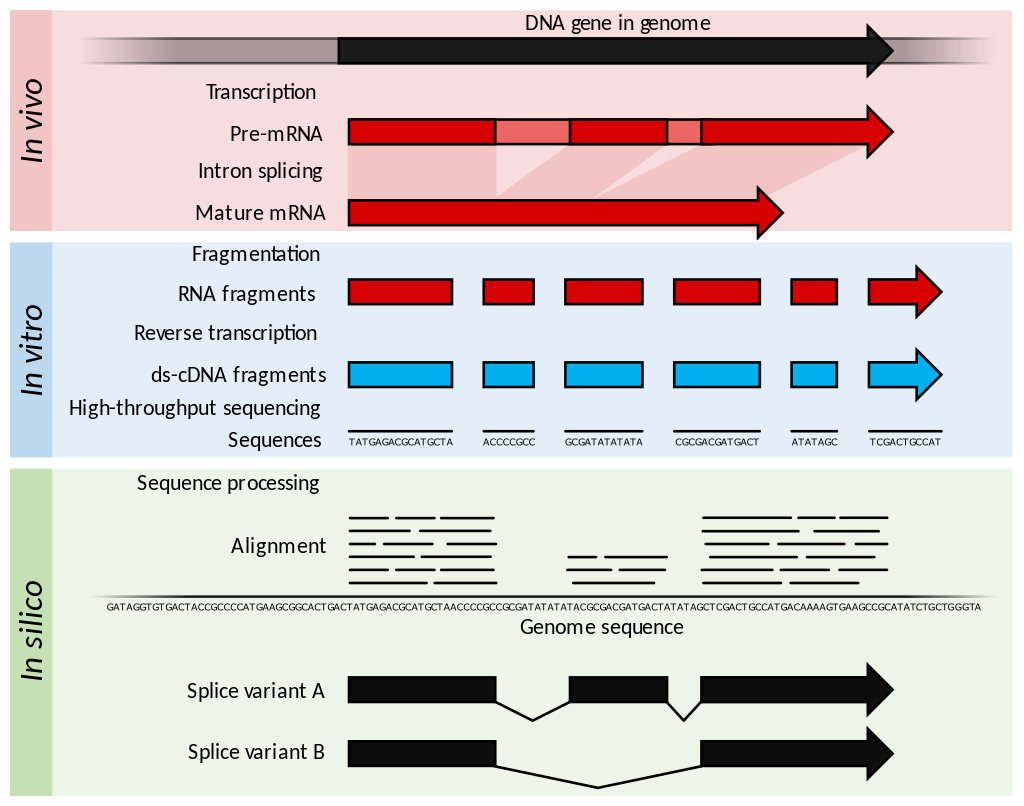
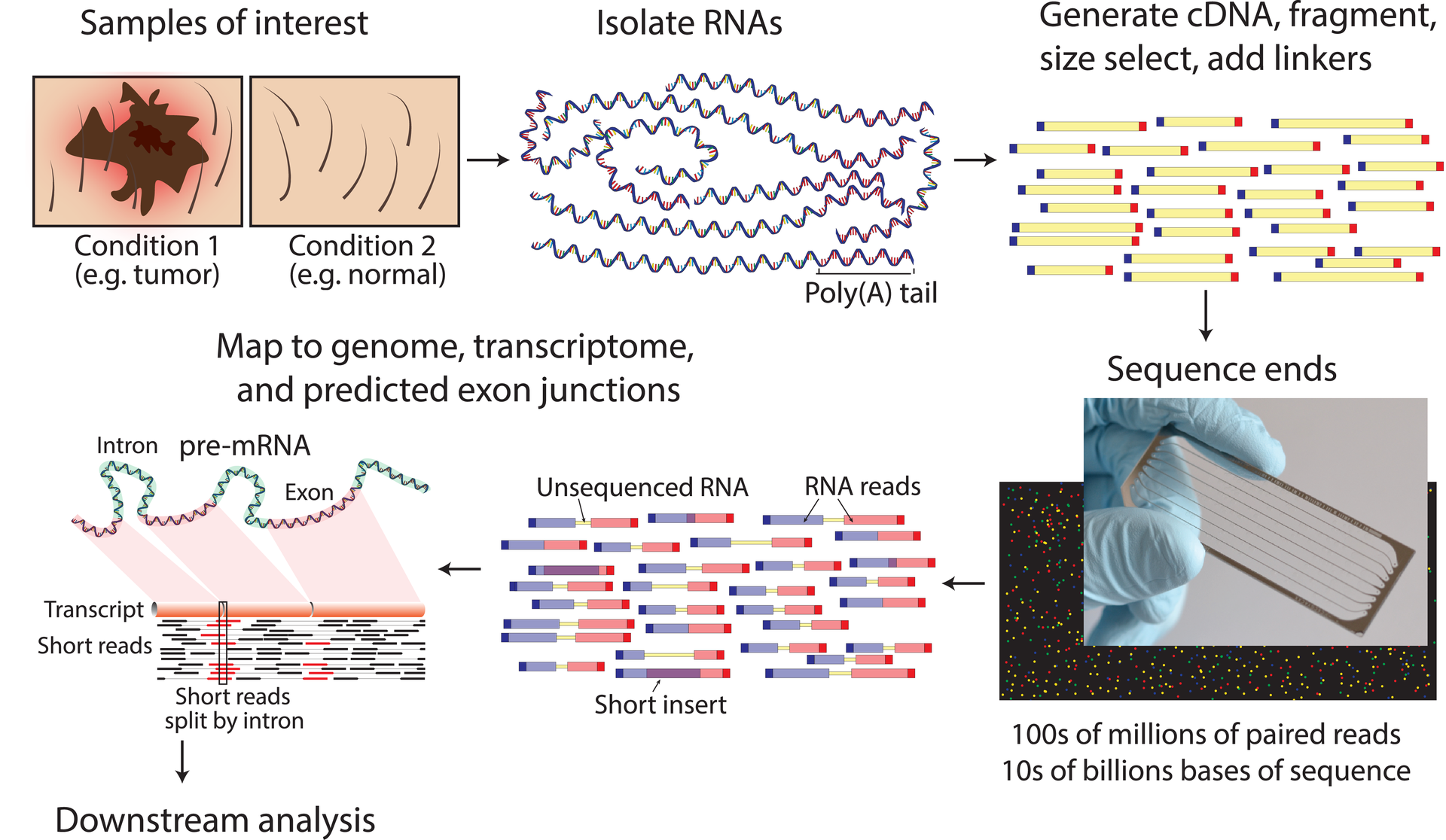
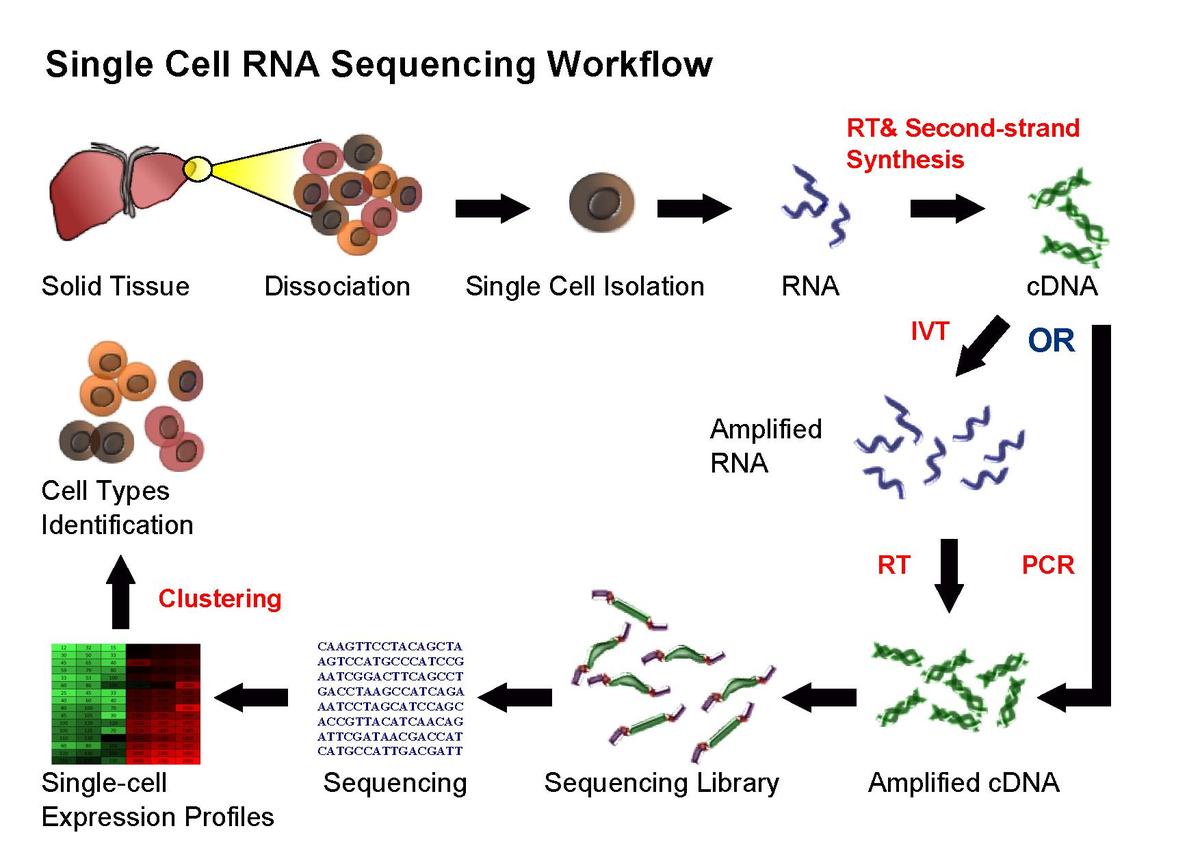
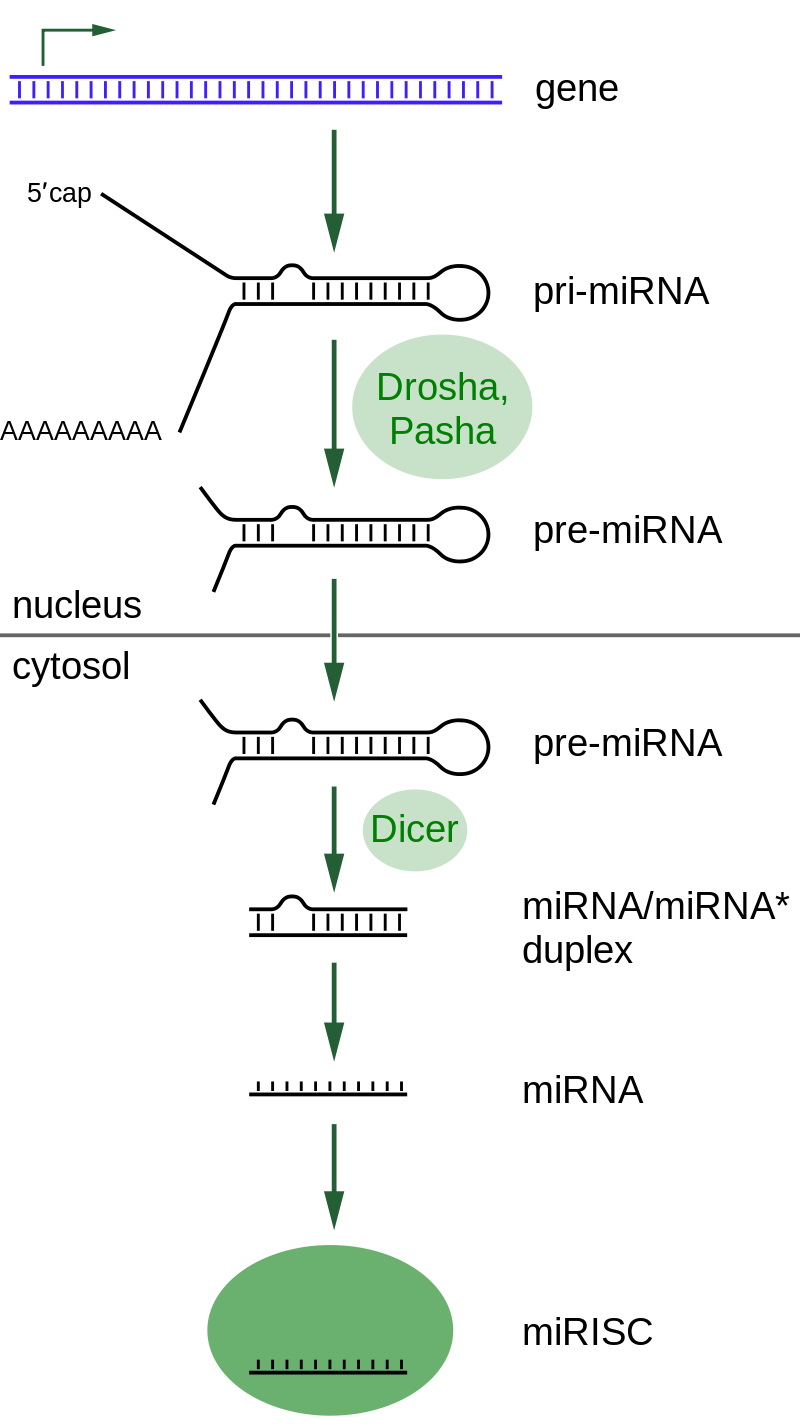
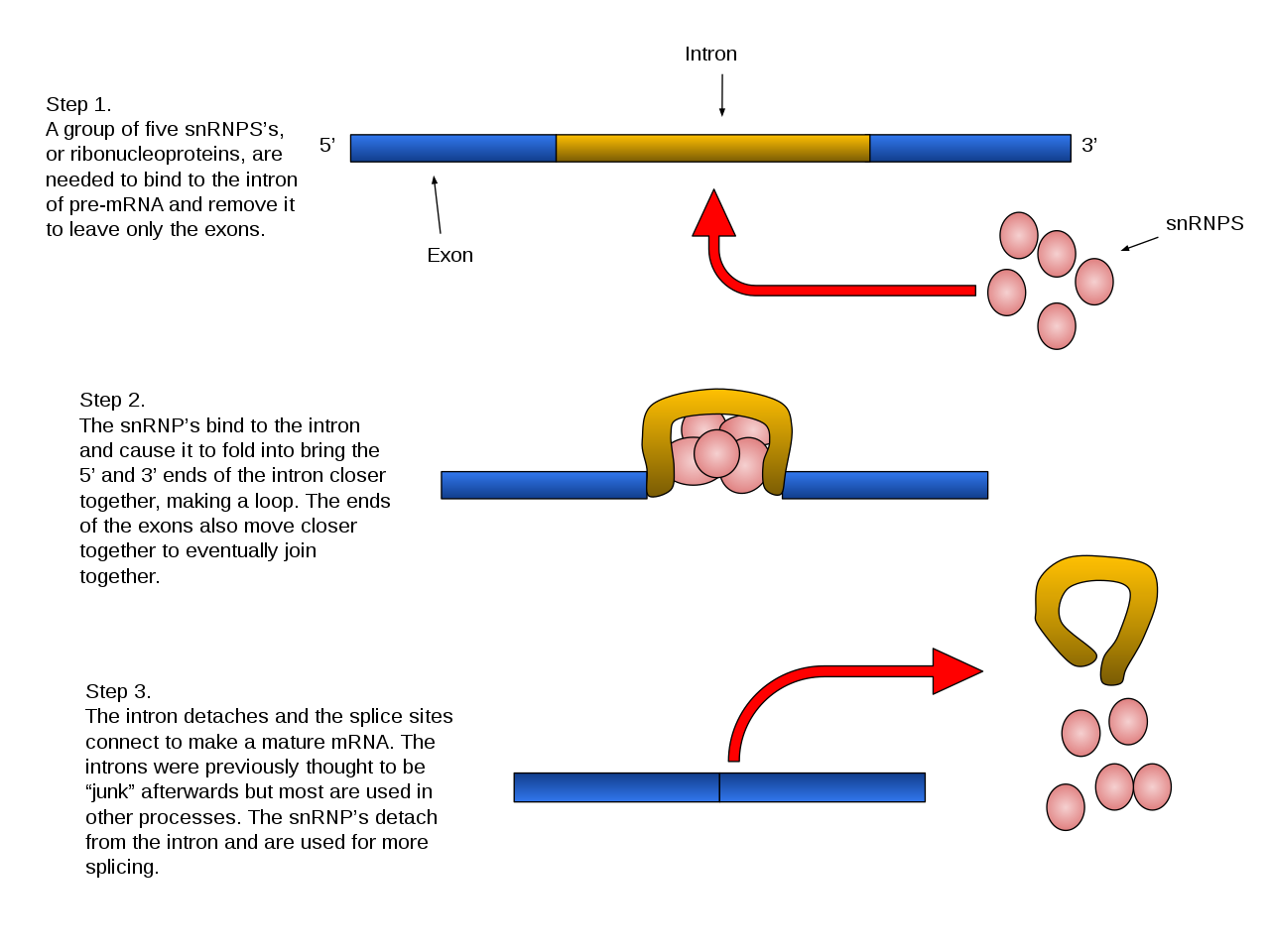
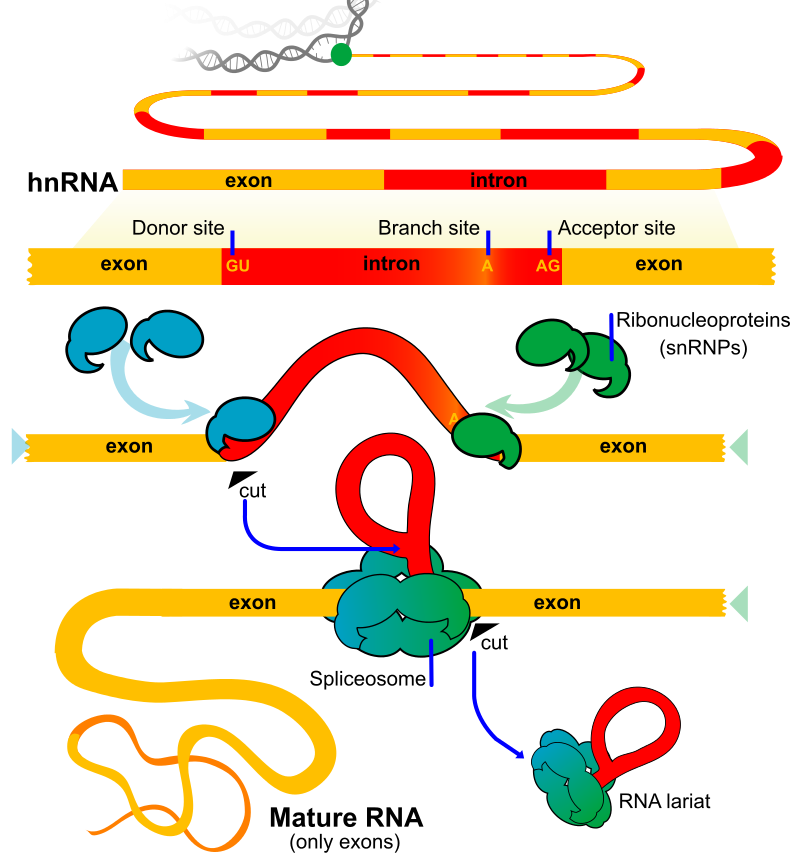
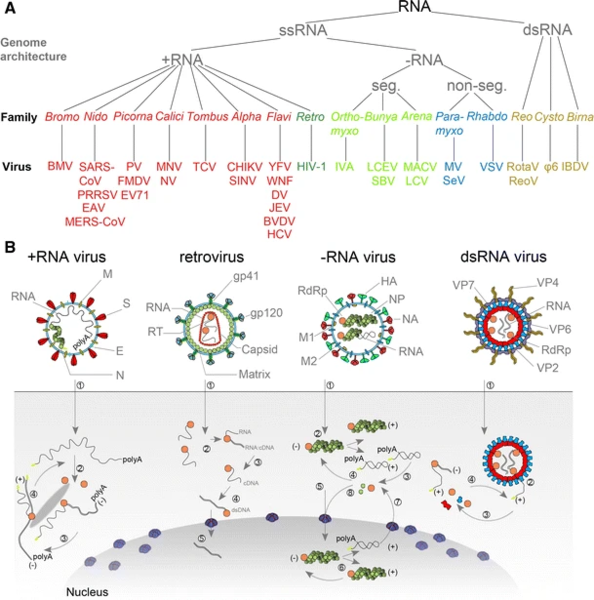
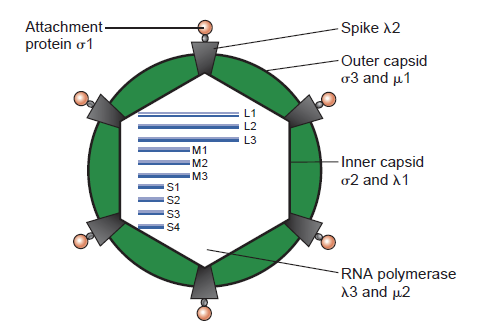
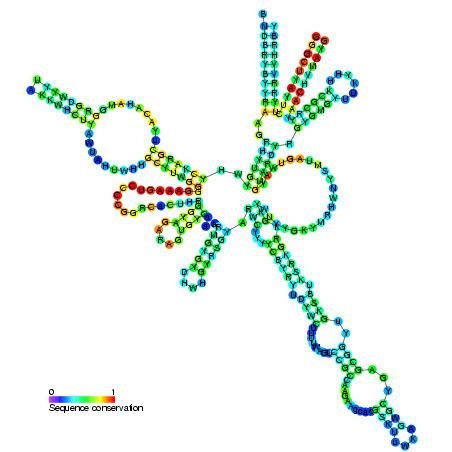
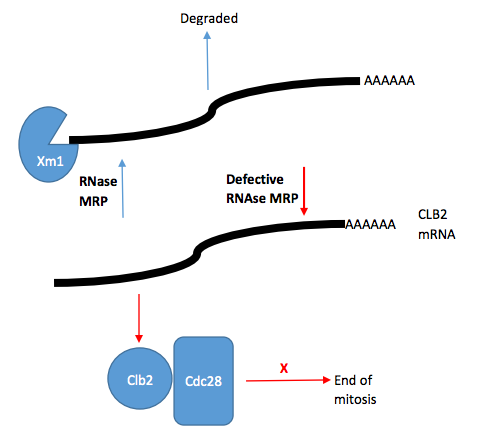
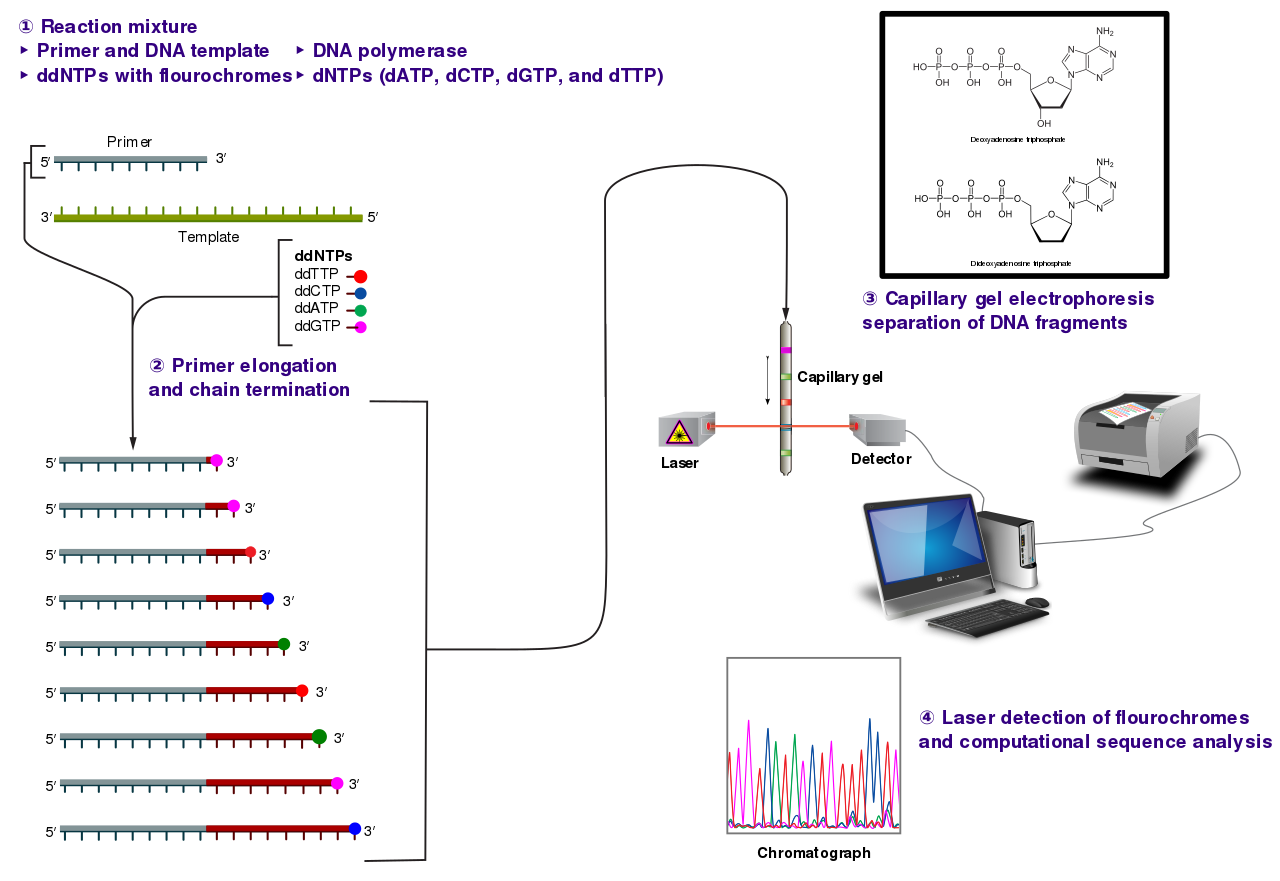
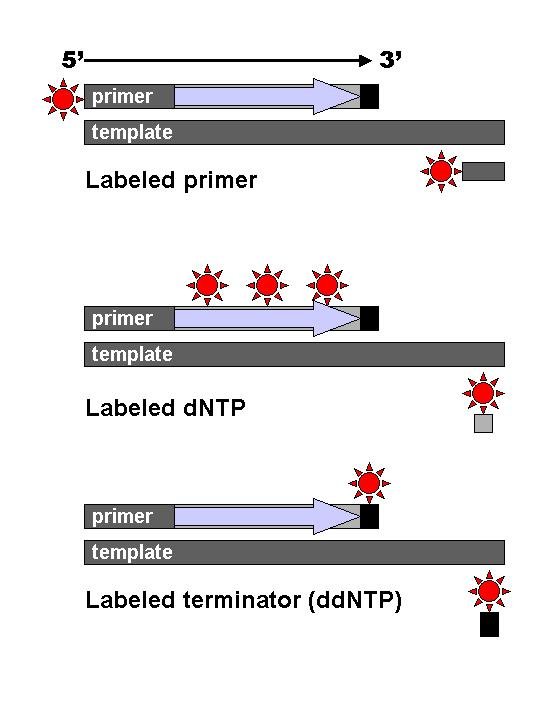
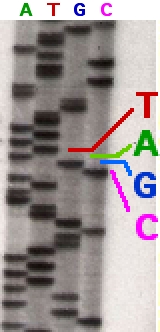
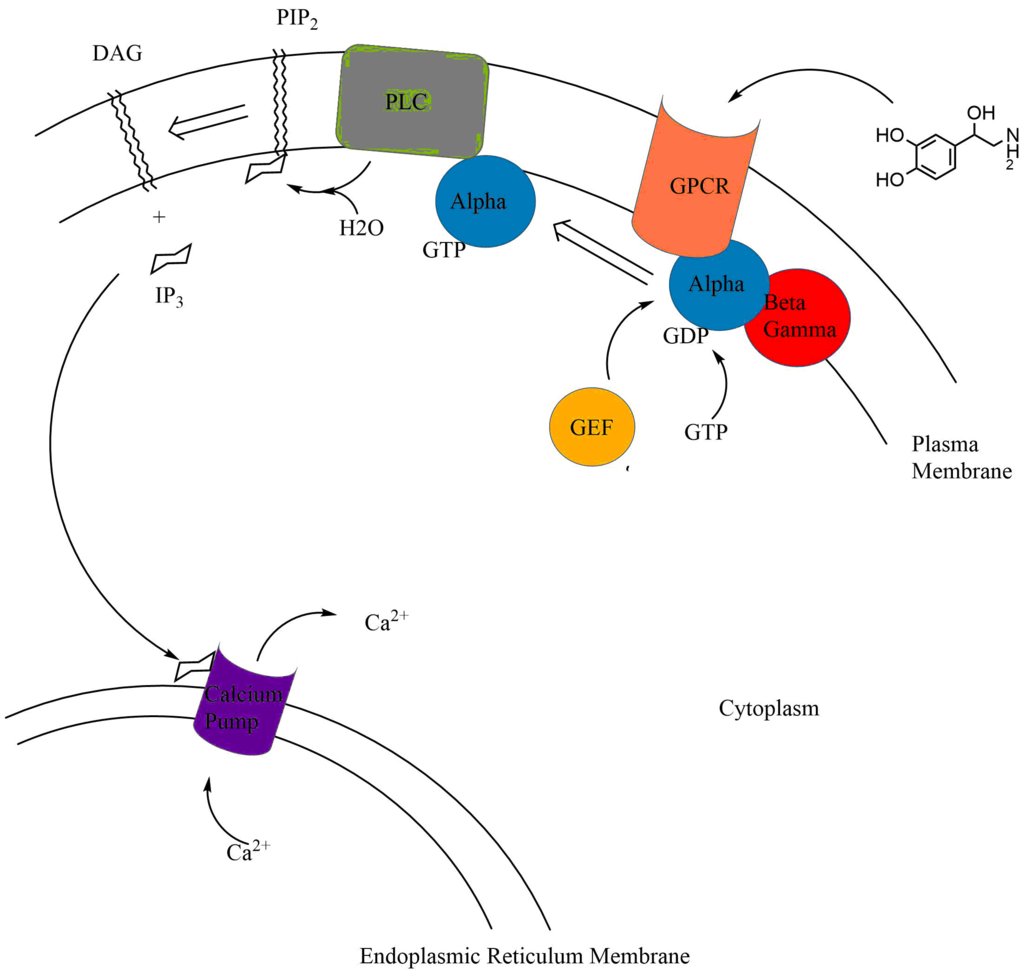
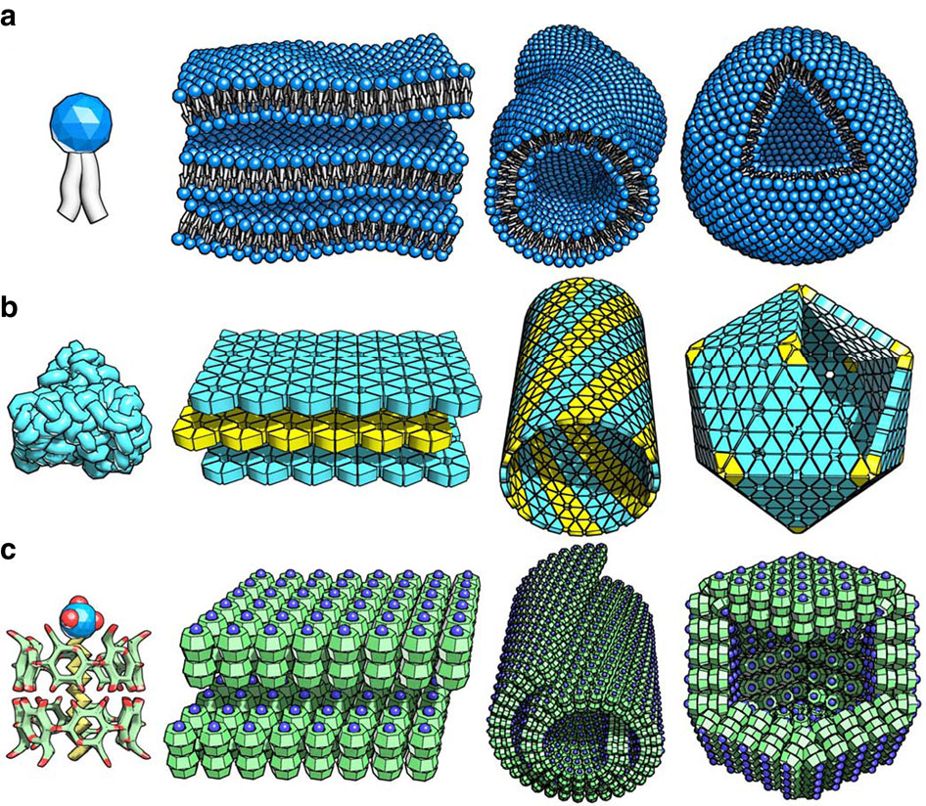

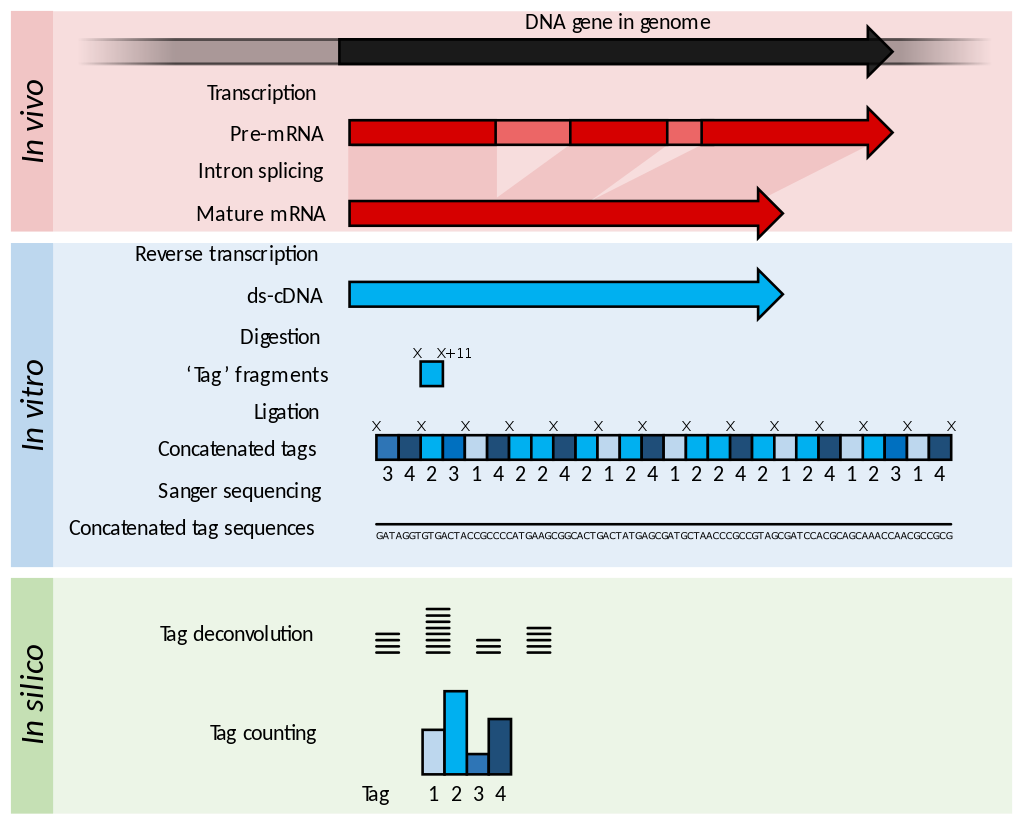
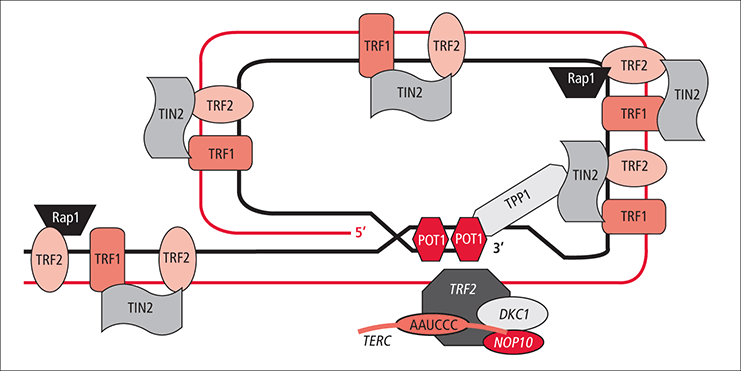
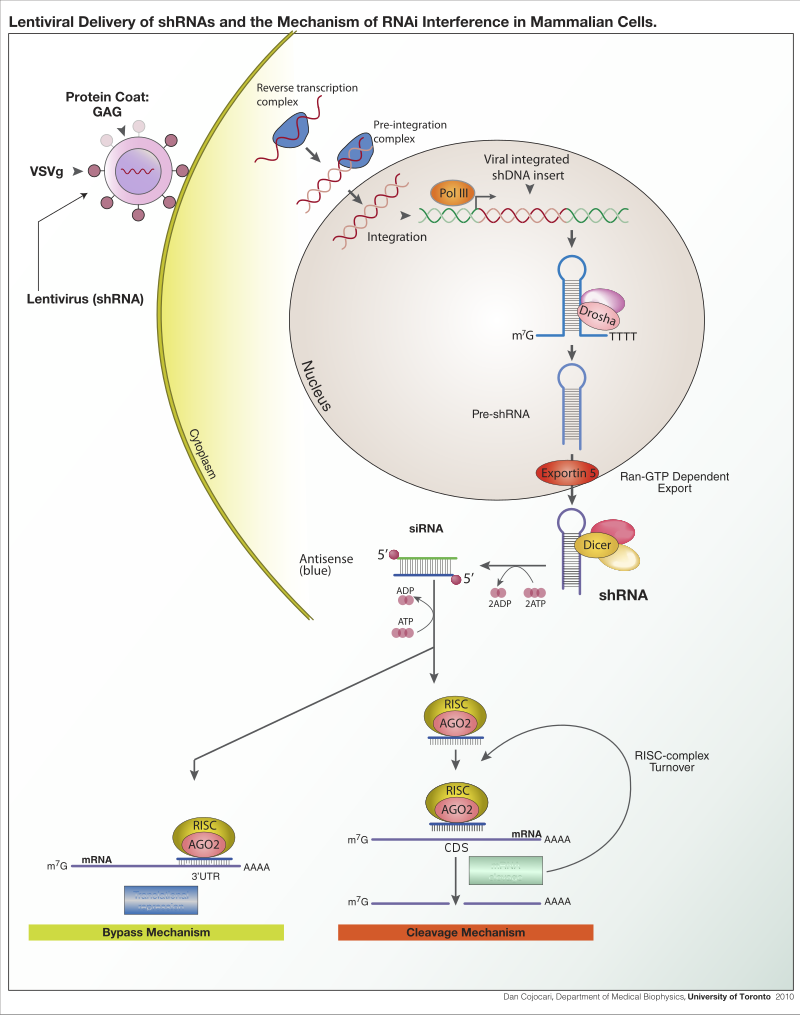
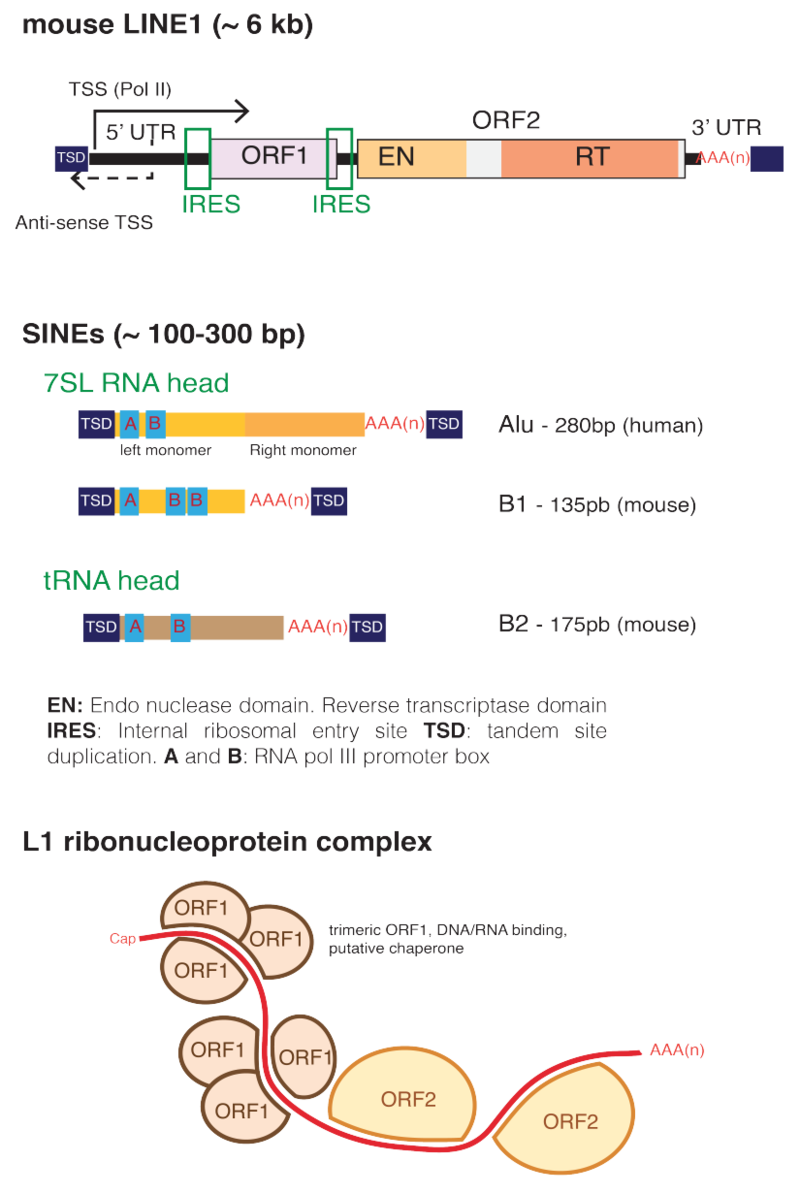
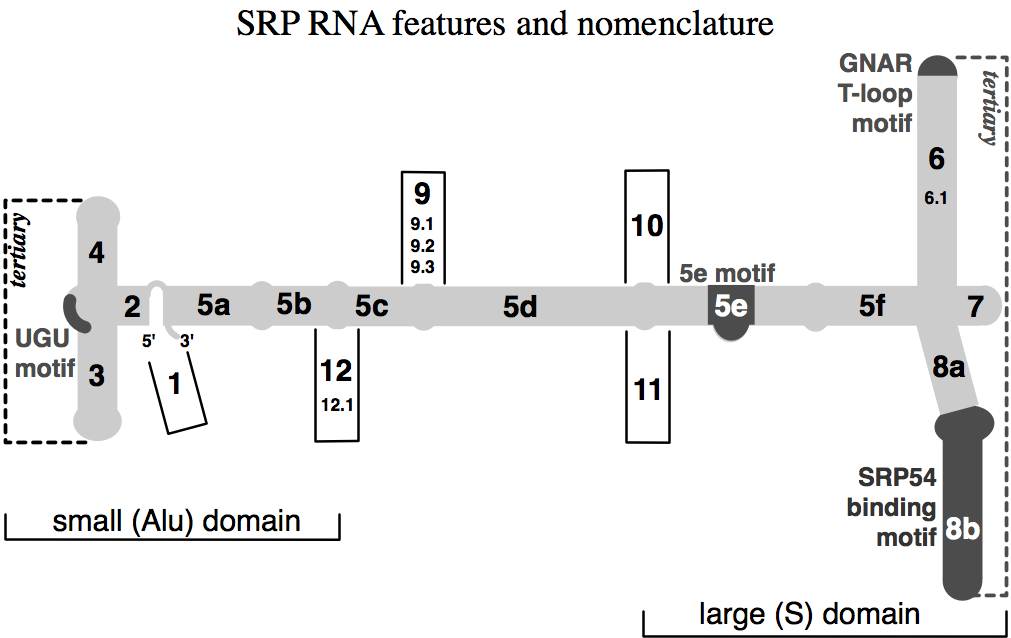

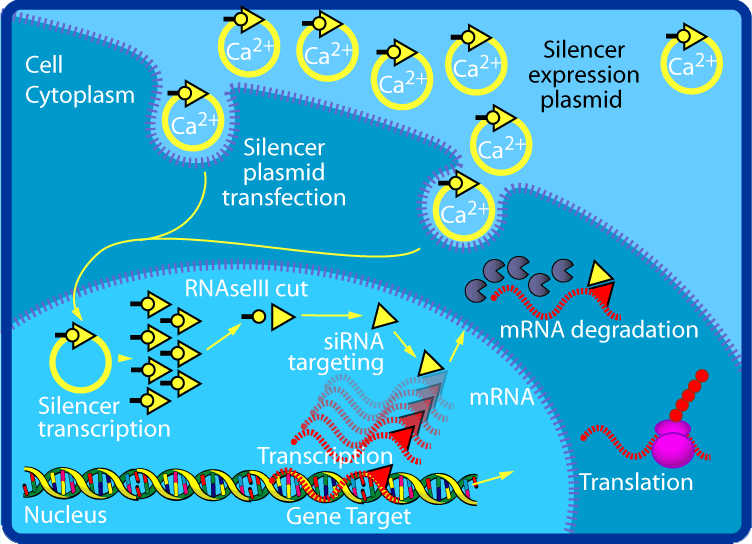
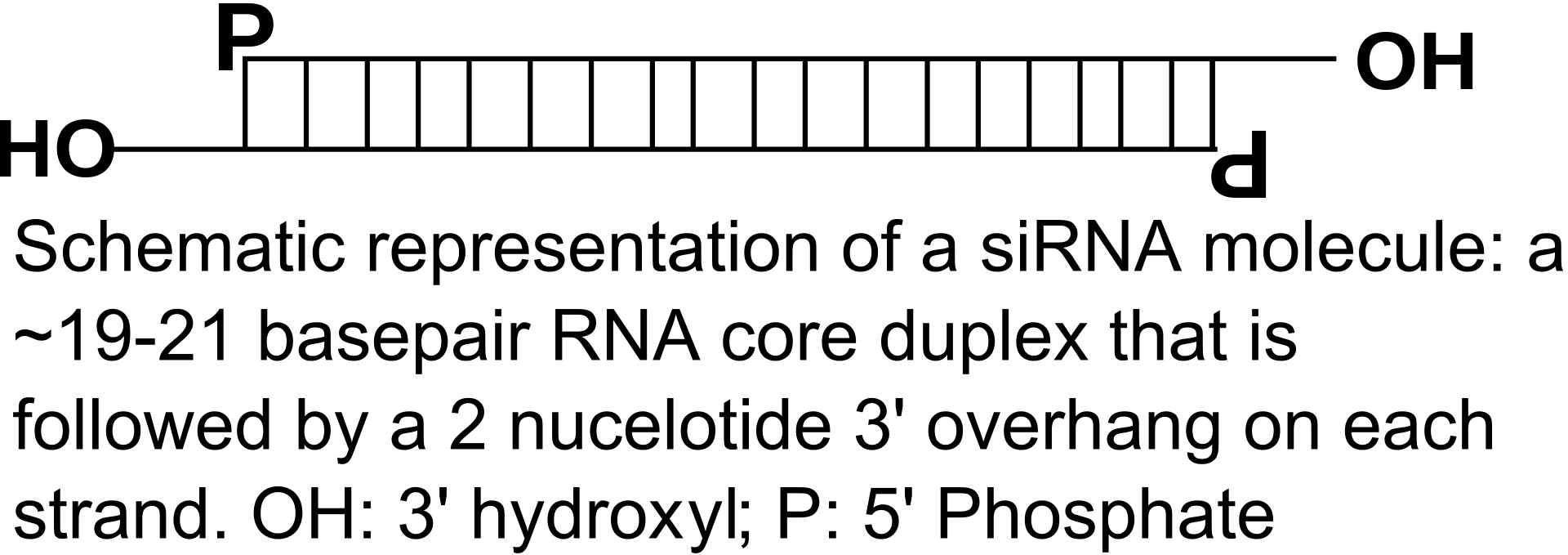
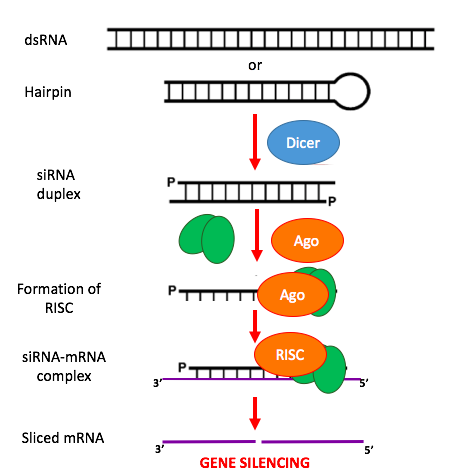
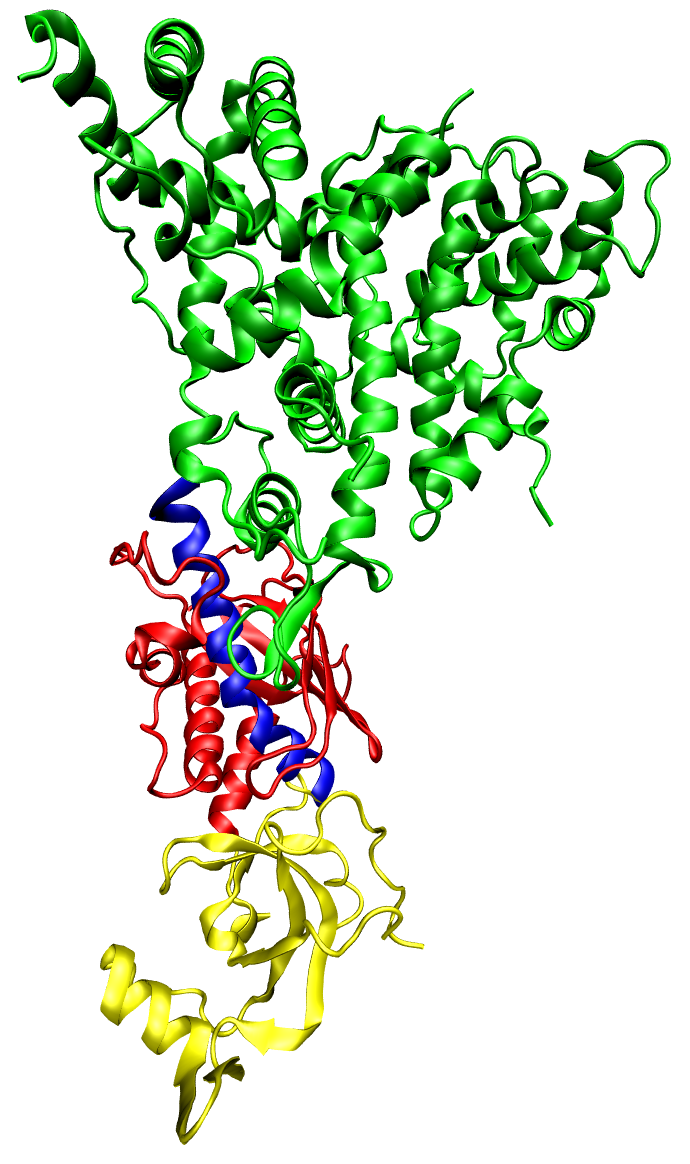
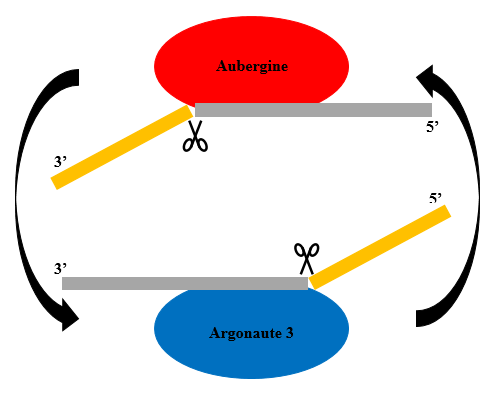
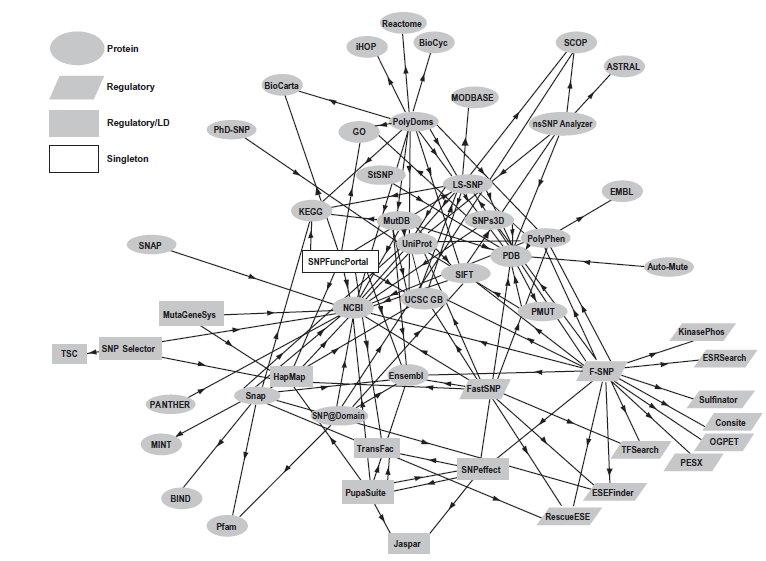
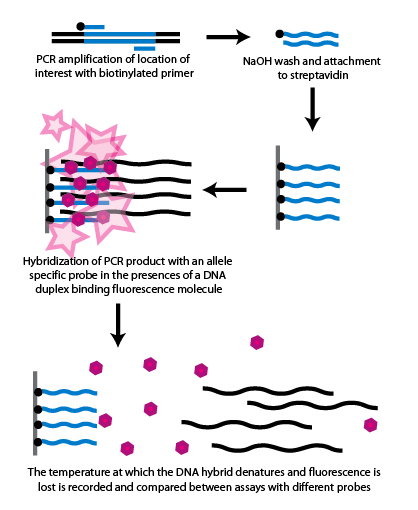
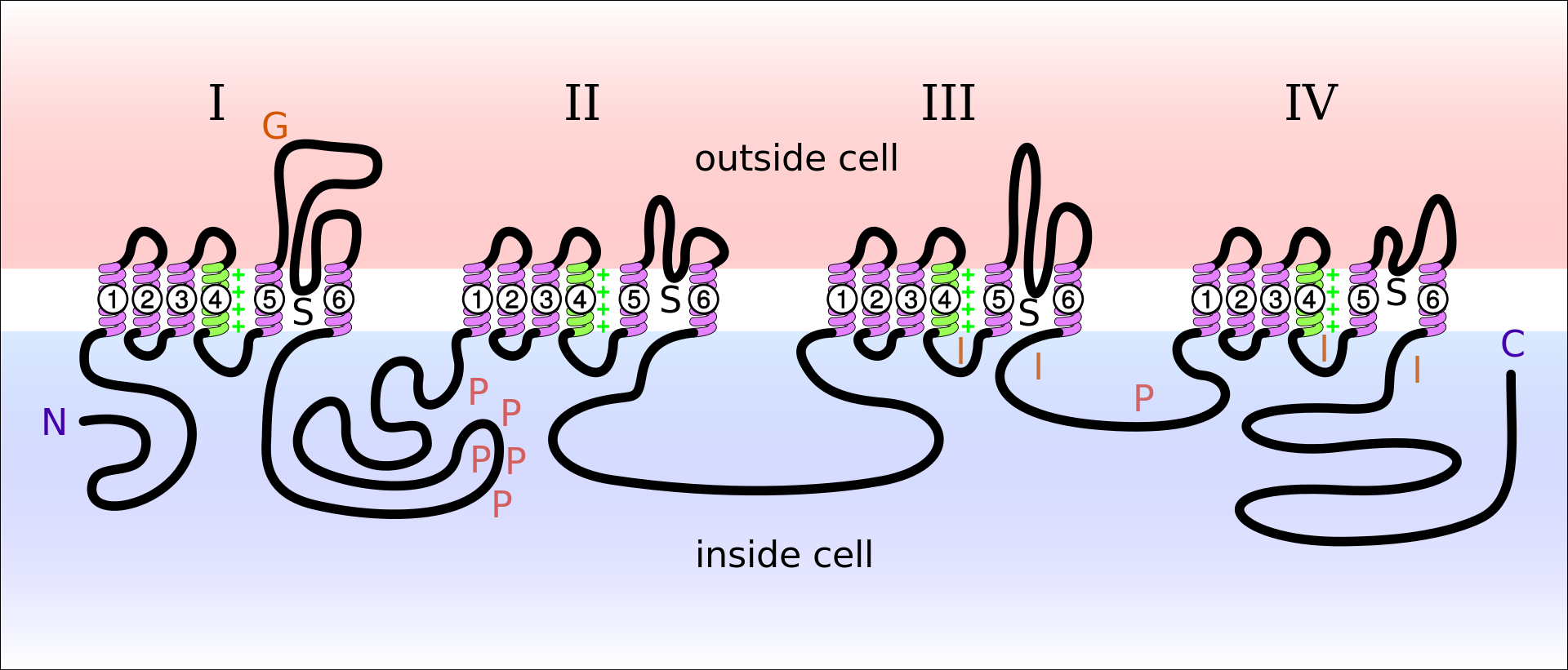

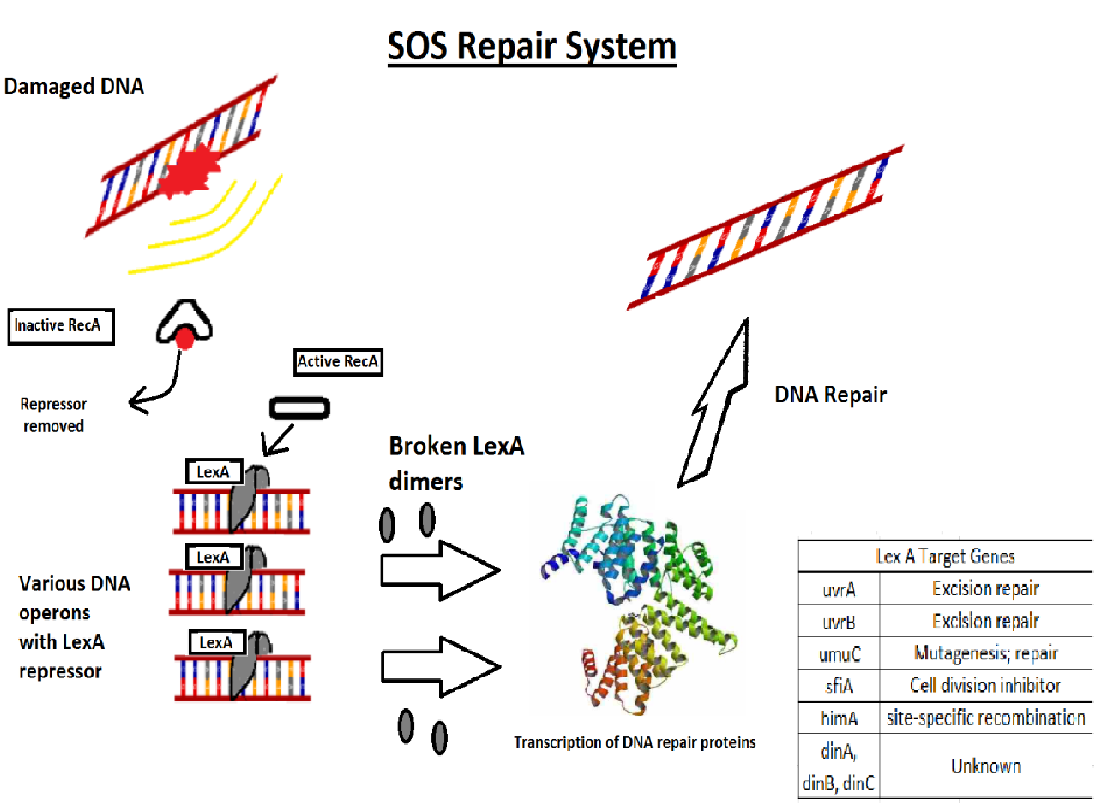
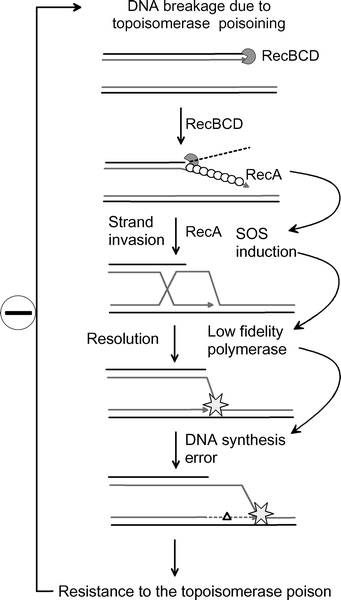
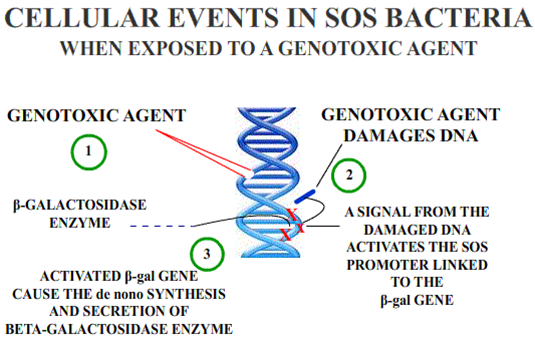

.jpg)
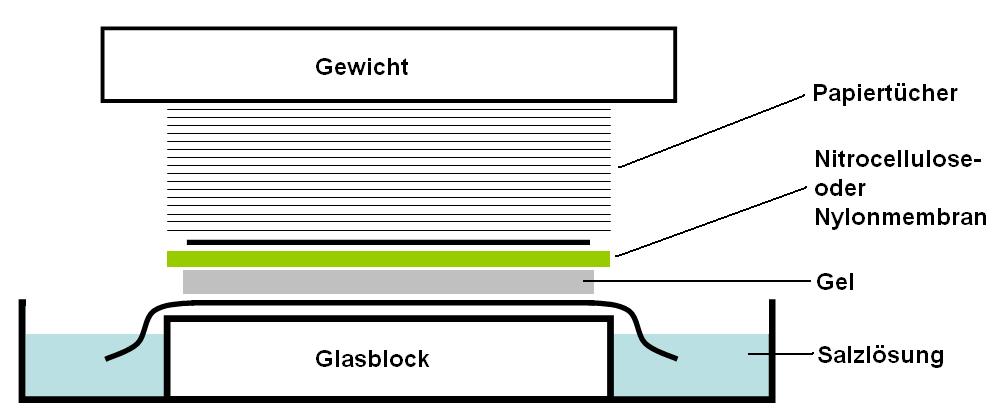
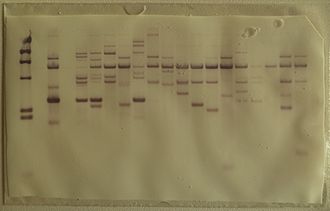



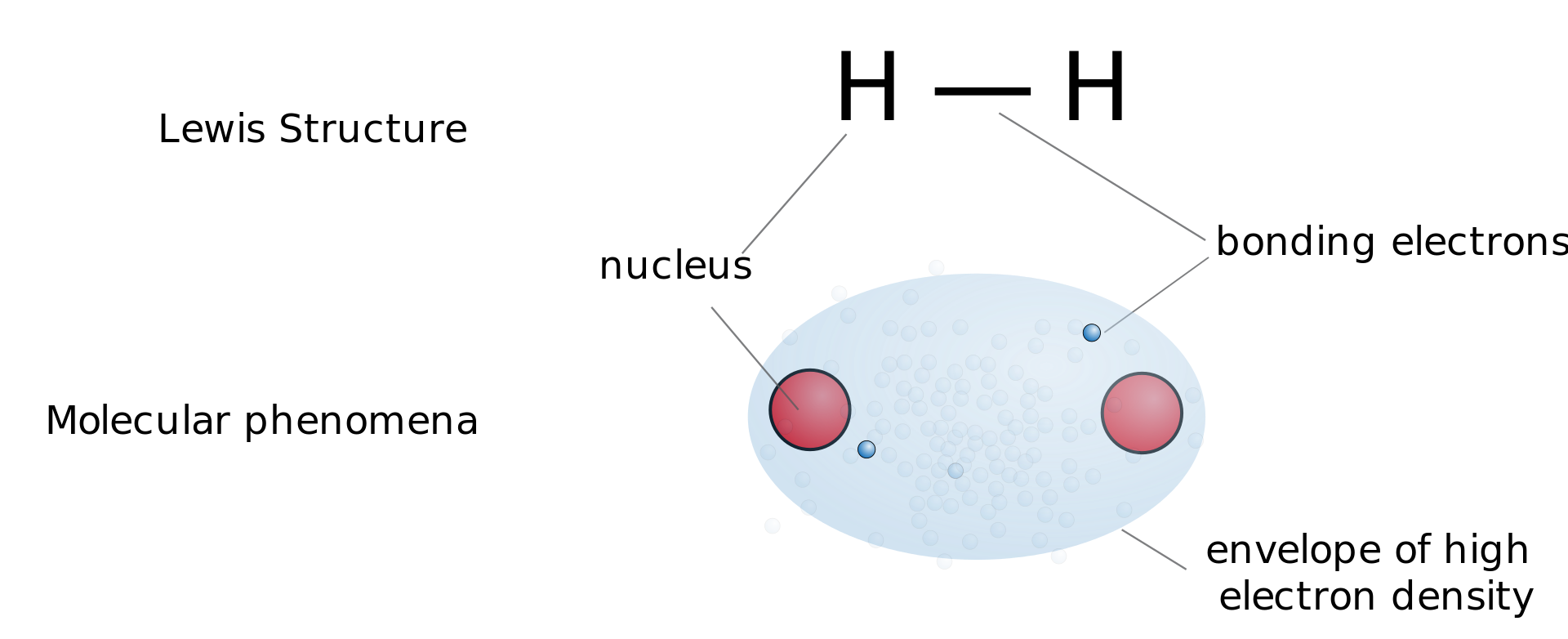
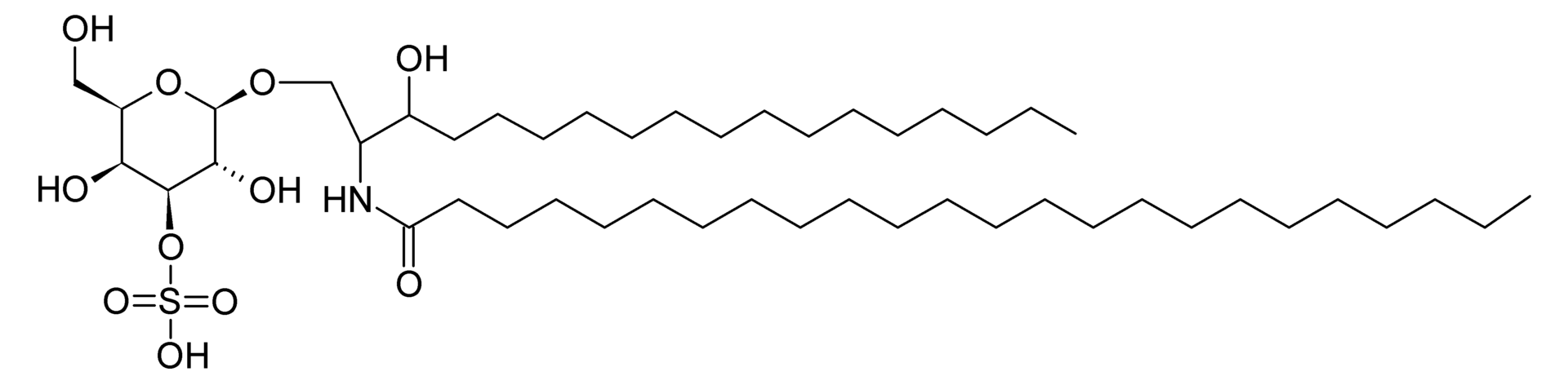
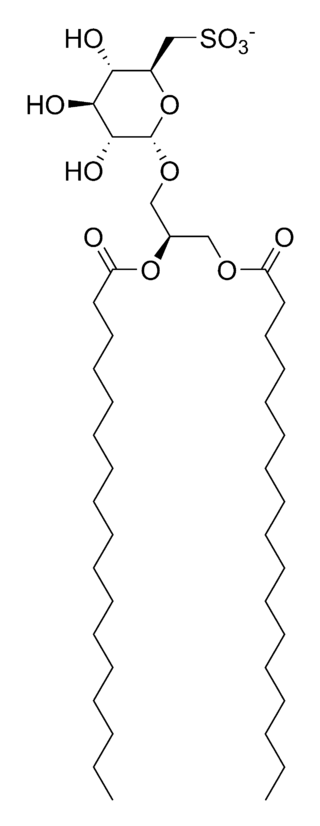
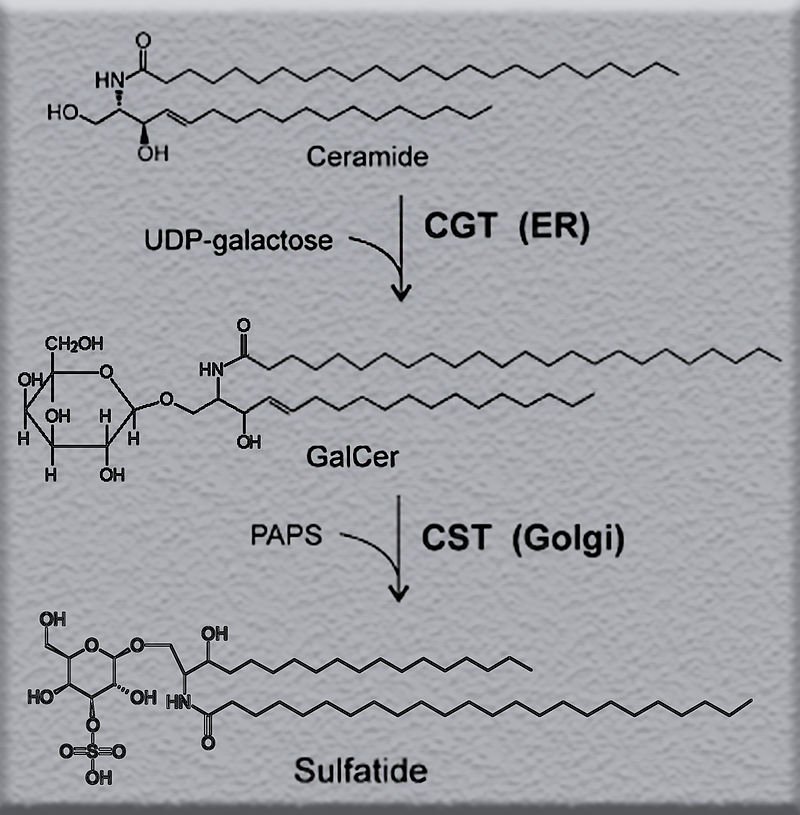
{kind=link}